“The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it. An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problem now reserved for humans, and improve themselves.”
\(~\) – Proposal for the Dartmouth AI program, 1956
This manuscript systematically introduces mathematical principles and computational mechanisms for how memory or empirical knowledge can be developed from observed high-dimensional data. The ability to seek parsimony in a seemingly random world is a fundamental characteristic of any intelligence, natural or artificial. We believe the principles and mechanisms presented in this book are unifying and universal, applicable to both animals and machines.
We hope this book helps readers fully clarify the mystery surrounding modern practices of artificial deep neural networks by developing a rigorous understanding of their functions and roles in learning (representations of) low-dimensional distributions from high-dimensional data. With this understanding, the capabilities and limitations of existing AI models and systems become clear:
One goal of this book is to help readers establish an objective and systematic understanding of current machine intelligence technologies and to recognize what open problems and challenges remain for further advancement of machine intelligence. In the last chapter, we provide some of our views and projections for the future.
From the practice of machine intelligence in the past decade, it has become clear that, given sufficient data and computational resources, one can build a large enough model and pre-train it to learn the prior distribution of all the data, say \(p(\vx )\). Theoretically, such a large model can memorize almost all existing knowledge about the world that is encoded in data such as 2D images, 3D shapes, dynamical motions, and natural languages. As we discussed at the beginning of the book, such a large model plays a role similar to DNA, which life uses to record and pass on knowledge about the world.
The model and distribution learned in this way can then be used to create new data samples drawn from the same distribution. One can also use the model to conduct inference (e.g., completion, estimation, and prediction) with the memorized knowledge under various conditions, say by sampling the posterior distribution \(p(\vx \mid \vy )\) under a new observation \(\vy \). Strictly speaking, such inference is inductive or statistical.
Any pre-trained model, however large, cannot guarantee that the distribution it has learned so far is entirely correct or complete. If our samples \(\hat {\vx }_{t}\) from the current prior \(p_{t}(\vx )\) or estimates \(\hat {\vx }_{t}(\vy )\) based on the posterior \(p_{t}(\vx \mid \vy )\) are inconsistent with the truth \(\vx \), we would like to correct the learned distributions:
based on the error \(\ve _{t} = \vx _{t} - \hat {\vx }_{t}\). This is known as error correction based on error feedback, a ubiquitous mechanism in nature for continuous learning. However, any open-ended model itself lacks the mechanism to revise or improve the learned distribution when it is incorrect or incomplete. Improving current AI models still depends largely on human involvement: supervision or reinforcement through experimentation, evaluation, and selection. We may call this process “artificial selection” of large models, as opposed to the natural selection for the evolution of life.
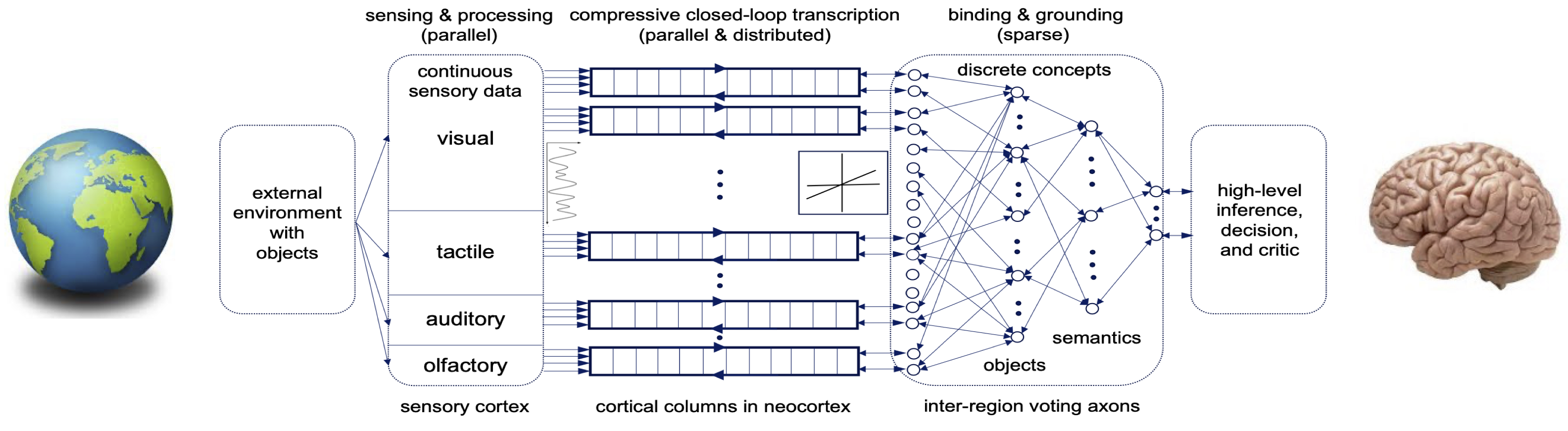
As we studied earlier in this book (Chapter 6 in particular), closed-loop systems align an internal representation with sensed observations of the external world. They can continuously improve the internally learned distribution and its representation to (incrementally) achieve consistency or self-consistency. An immediate next step is to develop truly closed-loop memory systems, illustrated in Figure 9.1, that autonomously and continuously learn general data distributions and improve based on error feedback.
Therefore, the transition from the currently popular end-to-end trained open-loop models to continuously learning closed-loop systems
is the key for machines to truly emulate how the animal brain learns and applies knowledge in an open world. We believe that
open-ended models are for a closed world, however large;
closed-loop systems are for an open world, however small.
Hence, the so-called “artificial general intelligence” (AGI) can never be achieved by simply having a system to memorize all existing data and knowledge of the world. No knowledge, however much, is truly generalizable.1 Nevertheless, it is the ability to improve one’s existing memory or knowledge and adapt to any new environments that is truly generalizable. Hence, truly genuine intelligence is itself generalizable if realized completely and correctly.2 This is precisely the essence of the Cybernetics program laid out by Norbert Wiener in the 1940s that we discussed at the very beginning of this book.
The practice of machine intelligence in recent years has led many to believe that one must build a single large model to learn the distribution of all data and memorize all knowledge. Even though this is technologically possible, such a solution is likely far from necessary or efficient. As we know from training deep networks, the only known scalable method to train such networks at scale is through back propagation (BP) [RHW86b]. Although BP offers a way to correct errors via gradient signals propagated back through the whole model, it is nevertheless rather brute-force and differs significantly from how nature learns: BP is an option that nature cannot afford due to its high cost and simply cannot implement due to physical limitations.
More generally, we cannot truly understand intelligence unless we also understand how it can be efficiently implemented. That is, one needs to address the computational complexity of realizing mechanisms associated with achieving the objectives of intelligence. Historically, our understanding of (machine) intelligence has evolved through several phases, from the incomputable Kolmogorov complexity to Shannon’s entropy, from Turing’s computability to later understanding of tractability,3 and to the strong emphasis on algorithm scalability in modern practice of high-dimensional data analysis [WM22] and artificial intelligence. This evolution can be summarized as follows:
To a large extent, the success and popularity of deep learning and back propagation is precisely because they have offered a scalable implementation with modern computing platforms (such as GPUs) for processing and compressing massive data. Nevertheless, such an implementation is still far more expensive than how nature realizes intelligence.
There remains significant room to improve the efficiency of machine intelligence so that it can emulate the efficiency of natural intelligence, which should be orders of magnitude greater than current brute-force implementations. To this end, we need to discover new learning architectures and optimization mechanisms that enable learning data distributions under natural physical conditions and resource constraints, similar to those faced by intelligent beings in nature—for example, without accessing all data at once or updating all model parameters simultaneously (via BP).
The principled framework and approach laid out in this book can guide us to discover such new architectures and mechanisms. These new architectures and mechanisms should enable online continuous learning and should be updatable through highly localized and sparse forward or backward optimization.4
As we have learned from neuroscience, the cortex of our brain consists of tens of thousands of cortical columns [Haw21]. All cortical columns have similar physical structures and functions. They are highly parallel and distributed, though sparsely interconnected. Hence, we believe that to develop a more scalable and structured memory system, we need to consider architectures that emulate those of the cortex. Figure 9.2 shows such a hypothesized architecture: a massively distributed and hierarchical system consisting of many largely parallel closed-loop auto-encoding modules.5 These modules learn to encode different sensory modalities or many projections of data from each sensory modality. Our discussion in Section 7.5 of Chapter 7 suggests that such parallel sensing and learning of a low-dimensional distribution is theoretically possible. Higher-level (lossy) autoencoders can then be learned based on outputs of lower-level ones to develop more sparse and higher-level “abstractions” of the representations learned by the lower levels.
The distributed, hierarchical, and closed-loop system architecture illustrated in Figure 9.2 shares many characteristics of the brain’s cortex. Such a system architecture may open up many more possibilities than the current single large-model architecture. In particular, it would lead to new optimization mechanisms that support continuouss self-supervised online learning and result in an ever more structured and rich representation of the sensed data of an open world. Such a system would truly emulate how the memory in our brain works. It would also allow us to transform the cuurently scalable implementation of machine intelligence into a new continous learning paradigm that achieves or even surpasses the effectiveness andefficiency of intelligence in nature:
As we have discussed at the beginning of this book, Chapter 1, intelligence in nature has evolved through multiple phases and manifested in at least four distinct forms:
All forms of intelligence share the common objective (and characteristic) of learning useful memory or knowledge as low-dimensional distributions of high-dim data sensed from the open world. Nevertheless, they differ in the specific code books or coding schemes adopted for encoding the useful information or knowledge, the specific information or knowledge encoded by the individual or a group, the computational mechanisms for acquiring and improving the encoded information or knowledge, and the physical substrate and implementation of such mechanisms. Using the concepts and terminology developed in this book, the four stages of intelligence differ in the following three aspects:
Table 9.1 summarizes their main characteristics:
| Phylogenetic | Ontogenetic | Societal | Scientific | |
| Codebook | DNAs | Neurons/Brain | Natural Languages | Math Abstractions |
| Information | Genes | Memory | Empirical Knowledge | Scientific Facts |
| Optimization | Reinforcement | Error Feedback | Trial & Error | Theorize & Falsify |
As we now know, humans have achieved two quantum leaps in intelligence:
The language of mathematics freed us from summarizing knowledge from observations only in empirical form and allowed us to formalize knowledge as theories verifiable or falsifiable through mathematical deduction or experimentation. Through hypothesis formulation, logical deduction, and experimental verification or falsification, we can now proactively discover and develop new knowledge that is far beyond what can be learned from the distributions of sensed data. For example, causal relationships cannot be learned from distributions alone [Pea09].
Despite the seeming differences among these different stages of intelligence, the evolution of intelligence shares a common characteristic: they all use certain forms of feedback6 to create and correct information learned, and the feedback and correction are becoming increasingly frequent and efficient through evolution—from open-loop reinforcement to closed-loop self-supervision, from collective trial and error to proactive hypothesizing and falsification.
As discussed in the introduction (Chapter 1), the 1956 “artificial intelligence” (AI) program aimed precisely to study how to endow machines with scientific intelligence, i.e., high-level functions such as mathematical abstraction, causal inference, logical deduction, and problem solving that are believed to differentiate humans from animals:
As we have clarified repeatedly in this book, most technological advances in machine intelligence over the past decade or so, although carried out under the name “AI”, are actually more closely related to having machines imitate low-level forms of intelligence largely shared by both animals and humans, including phylogenetic, ontogenetic, and societal intelligence. At these levels, intelligence creates memory or empirical knowledge (from empirical data distributions) and conducts inference (or prediction) that is mostly inductive (or Bayesian-like) in nature. Principles and methods introduced in this book aim to reveal scientific objectives and computational mechanisms behind intelligence at these levels. They provide strong theoretical justification and computational evidence for the following claim:
Machines can learn empirical knowledge and conduct inductive inference.
So far, however, no rigorous theoretical or scientific evidence suggests that these mechanisms alone would suffice to achieve the high-level human intelligence that the original “artificial intelligence” program truly aimed to understand and wanted for machines to imitate or even surpass.
In fact, as of today, we know little about how to rigorously verify or certify whether a system is truly capable of such high-level intelligence, even though the Turing Test, also known as the Imitation Game, was proposed in 1950 [Tur50], as an initial attempt to address the fundamental question:
Can machines think?
However, in Turing’s proposal, the evaluator, or interrogator, is some human. However, most human evaluators have limited scientific training and knowledge, and their conclusions can be rather subjective.
For a long time, a precise definition of such a test was not deemed necessary since machine capabilities were far below those of humans (or even animals). However, given recent technological advances, many models and systems now claim to have reached or even surpassed human intelligence. Therefore, it is high time to develop a scientific and executable definition of the Turing Test, i.e., a systematic and rigorous protocol to evaluate and certify the intelligence level of a model or a system that claims to be “intelligent.”
As Turing argued in his original paper, it is rather difficult to define what “thinking” really means. We may instead start with something arguable more tangible and try to determine first whether the system in question can truly “understand” certain abstract concepts or knowledge. For example, we may try to verify whether an intelligent model or system has truly understood an abstract concept such as:
just to name a few? Or has it simply memorized a massive number of examples of such notions? Note that state-of-the-art large language models still struggle with simple mathematical questions like: “Is 3.11 larger or smaller than 3.9?”8
From this book, we know modern generative AI systems primarily rely on Bayesian (hence inductive) inference to produce their answers. Can machines also truly grasp mathematical induction or general logical deduction and understand its difference from Bayesian induction? How do we verify whether a system truly understands the rules of logical and mathematical deduction and can apply them rigorously? Or, again, has it merely memorized statistical patterns of such deductions from a large number of instances, such as chain-of-thought data, and simply exploited such patterns inductively during inference? Hence the following question remains an open one:
Is there any difference between memorizing and understanding?
Only by clarifying the difference between these two can we possibly provide a meaningful answer to the question: “Can machines understand?”
Probably much more importantly, how do we verify whether a self-claimed intelligent system is capable of creating abstract concepts or improving its own knowledge proactively via deductive means? For example, can it create new mathematical concepts and discover new physical laws or causal relationships? The connection between understanding and creating can be rather profound, as the physicist Richard Feynman had famously put it:
“What I cannot create, I do not understand.”
Hence, it is high time we develop scientifically sound evaluation methods to determine which of the following categories a system’s intelligence capability belongs to:
To evaluate and distinguish these different levels of intelligence, we suggest that there should probably be at least three different tests, as illustrated in Figure 9.3:
We believe that, for such tests, the evaluator, or interrogator, should not be a single human or an arbitrary group of humans but rather a scientifically certified entity following a scientifically sound protocol and process so that the conclusions would be rigorous and trustworthy.
As we have seen throughout this book, compression has played a fundamental role in developing a memory or creating empirical knowledge. It is the governing principle and a universal mechanism for identifying an empirical data distribution and organizing the information encoded therein with a structured representation. To a large extent, it explains the practice of “artificial intelligence” with deep networks, which is largely inductive and Bayesian in nature.9 An outstanding question for future study is whether compression alone is sufficient to achieve all the higher-level deductive intelligence mentioned above. In particular, are mathematical abstraction, causal inference, hypothesis generation, and logical reasoning and deduction some kind of extended or transcended forms of compression? Is there some fundamental difference between learning data distributions through compression and forming high-level concepts and theories through (mathematical) abstraction? Hence we have another open question:
Is there any difference between compression and abstraction?
Only by knowing the difference can we possibly attempt to provide a meaningful answer to the question: “Can machines create knowledge proactively via deduction?”
To a large extent, Science—and its associated code book, Mathematics—can be viewed as the most advanced form of intelligence. It is largely deductive in nature and unique to educated and enlightened humans. Philosopher Sir Karl Popper once suggested:
“Science may be described as the art of systematic oversimplification.”
We believe that uncovering and understanding the underlying mathematical principles and computational mechanisms of such higher-level intelligence, and successfully reproducing them through machines, will be the final frontier for Science, Mathematics, and Computation altogether!