“The art of doing mathematics consists in finding that special case which contains all the germs of generality.”
\(~\) – David Hilbert
Real data has low-dimensional structure. To see why this is true, let us consider the unassuming case of static on a TV when the satellite isn’t working. At each frame (approximately every \(\frac {1}{30}\) seconds), the RGB static on a screen of size \(H \times W\) is, roughly, sampled independently from a uniform distribution on \([0, 1]^{3 \times H \times W}\). In theory, the static could resolve to a natural image on any given frame, but even if you spend a thousand years looking at the TV screen, it will not. This discrepancy is explained by the fact that the set of \(H \times W\) natural images takes up a vanishingly small fraction of the hypercube \([0, 1]^{3 \times H \times W}\). In particular, it is extremely low-dimensional, compared to the ambient space dimension. Similar phenomena occur for all other types of natural data, such as text, audio, and video. Thus, when we design systems and methods to process natural data and learn its structure or distribution, this is a central property of natural data which we need to take into account.
Therefore, our central task is to learn a distribution that has low intrinsic dimension in a high-dimensional space. In the remainder of this chapter, we discuss several classical methods to perform this task for several somewhat idealistic models for the distribution, namely models that are geometrically linear or statistically independent. While these models and methods are important and useful in their own right, we discuss them here as they motivate, inspire, and serve as a predecessor or analogue to more modern methods for more general distributions that involve deep (representation) learning.
Our main approach (and general problem formulation) can be summarized as:
Problem: Given one or several (noisy or incomplete) observations of a ground truth sample from the data distribution, obtain an estimate of this sample.
This approach underpins several classical methods for data processing, which we discuss in this chapter.
In this chapter, as described above, we make simplifying modeling assumptions that essentially assume (the support of) the data distribution has geometrically (nearly, piece-wise) linear structures and statistically independent components, as illustrated in Figure 2.1.
In Chapter 1, we have referred to such models of the data as “analytical models”. These modeling assumptions allow us to derive efficient algorithms with provable efficiency guarantees, both in terms of data and computational complexity, for processing data at scale. However, they are imperfect models for often-complex real-world data distributions, and so their underlying assumptions only approximately hold. This means that the guarantees afforded by detailed analysis of these algorithms also only approximately hold in the case of real data.
Nonetheless, the techniques discussed in this chapter are useful in their own right, and beyond that, serve as the “special case with the germs of generality”, so to speak, in that they present a guiding motivation and intuition for the more general paradigms within (deep) learning of more general distributions that we later address. As we will soon reveal in later chapters, in the deep learning era, modern “data-driven” or “non-parametric” approaches to learn (low-dimensional) data distributions essentially adopt the same concepts and ideas to learn.
A Note on Notation. We encourage the reader to consult the Notation chapter, particularly the “Modeling and Optimization Notation” section, as they begin to go through this chapter. We use the same notational conventions for modeling data and optimizing the parameters of these models throughout the book, and the simple, explicit models we study in this chapter help make the ‘semantic’ content of these conventions clear.
Perhaps the simplest modeling assumption possible for low-dimensional structure is the so-called low-rank assumption. Letting \(D\) be the dimension of our data space, we assume that our data belong to a low-dimensional subspace of dimension \(d \ll D\), possibly plus some small disturbances.1 This ends up being a nearly valid assumption for some surprisingly complex data, such as images of handwritten digits and face data [RD03] as shown in Figure 2.2, yet as we will see, it will lend itself extremely well to comprehensive analysis.
Problem Formulation. To write this in mathematical notation, we represent a subspace \(\cS \subseteq \R ^{D}\) of dimension \(d\) by an orthonormal matrix \(\vU \in \O (D, d) \subseteq \R ^{D \times d}\) such that the columns of \(\vU \) span \(\cS \). Then, we say that our data \(\{\vx _{i}\}_{i = 1}^{N} \subseteq \R ^{D}\) have (approximate) low-rank structure if there exists an orthonormal matrix \(\vU \in \O (D, d)\), vectors \(\{\vz _{i}\}_{i = 1}^{N} \subseteq \R ^{d}\), and small vectors \(\{\veps _{i}\}_{i = 1}^{N} \subseteq \R ^{D}\) such that
Here \(\veps _{i}\) are disturbances that prevent the data from being perfectly low rank; their presence in our model allows us to quantify the degree to which our analysis remains relevant in the presence of deviations from our model. The true supporting subspace is \(\cS \doteq \mathop {\mathrm {col}}(\vU )\), the span of the columns of \(\vU \). To process all we can from these data, we need to recover \(\cS \); to do this it is sufficient to recover \(\vU \), also called the principal components. Fortunately, this is a computationally tractable task named Principal Component Analysis, and we discuss now how to solve it.
Given data \(\{\vx _{i}\}_{i = 1}^{N}\) distributed as in (2.1.1), we aim to recover the model \(\vU \). A natural approach is to find the subspace \(\vU ^{\star }\) and latent vectors \(\{\vz _{i}^{\star }\}_{i = 1}^{N}\) which yield the best approximation \(\vx _{i} \approx \vU ^{\star }\vz _{i}^{\star }\). Namely, we aim to solve the problem
where \(\tilde {\vU }\) is constrained to be an orthonormal matrix, as above. We will omit this constraint in similar statements below for the sake of concision.
Subspace Encoding-Decoding via Denoising. To simplify this problem, for a fixed \(\tilde {\vU }\), we have (proof as exercise):
That is, the optimal solution \((\vU ^{\star }, \{\vz _{i}^{\star }\}_{i = 1}^{N})\) to the above optimization problem has \(\vz _i^{\star } = (\vU ^{\star })^\top \vx _i\).
Now, we can write the original optimization problem in \(\tilde {\vU }\) and \(\{\tilde {\vz }_{i}\}_{i = 1}^{N}\) as an optimization problem just over \(\tilde {\vU }\), i.e., to obtain the basis \(\vU ^{\star }\) and compact codes \(\{\vz _{i}^{\star }\}_{i = 1}^{N}\) it suffices to solve either of the two following equivalent problems:
Note that the problem on the right-hand side of (2.1.5) is a denoising problem: given noisy observations \(\vx _{i}\) of low-rank data, we aim to find the noise-free copy of \(\vx _{i}\), which under the model (2.1.1) is \(\vU \vz _{i}\). That is, the denoised input \(\hat {\vx }_i = \vU \vU ^\top \vx _i\). Notice that this is the point on the subspace that is closest to \(\vx _i\), as visualized in Figure 2.3. Here by solving the equivalent problem of finding the best subspace, parameterized by the learned basis \(\vU ^{\star }\), we learn an approximation to the denoiser, i.e., the projection matrix \(\vU ^{\star }(\vU ^{\star })^{\top } \approx \vU \vU ^{\top }\) that projects the noisy data point \(\vx _i\) onto the subspace \(\cS \).
Putting the above process together, we essentially obtain a simple encoding-decoding scheme that maps a data point \(\vx \) in \(\R ^D\) to a lower-dimensional (latent) space \(\R ^d\) and then back to \(\R ^D\):
Here, \(\vz \in \R ^d\) can be viewed as the low-dimensional compact code (or a latent representation) of a data point \(\vx \in \R ^D\) and the learned subspace basis \(\vU ^\star \) as the associated codebook whose columns are the (learned) optimal code words. The process achieves the function of denoising \(\vx \) by projecting it onto the subspace spanned by \(\vU ^\star \).
Computing the Subspace Basis. For now, we continue our calculation. Let \(\vX = \mat {\vx _{1}, \dots , \vx _{N}} \in \R ^{D \times N}\) be the matrix whose columns are the observations \(\vx _{i}\). We have (proof as exercise)
Thus, to compute the principal components, we find the orthogonal matrix \(\tilde {\vU }\) which maximizes the term \(\tr (\tilde {\vU }^{\top }(\vX \vX ^{\top }/N)\tilde {\vU })\). We can prove via induction that this matrix \(\vU ^{\star }\) has columns which are the top \(d\) unit eigenvectors of \(\vX \vX ^{\top }/N\). We leave the whole proof to the reader in Exercise 2.1, but we handle the base case of the induction here. Suppose that \(d = 1\). Then we only have a single unit vector \(\vu \) to recover, so the above problem reduces to
This is the so-called Rayleigh quotient of \(\vX \vX ^{\top }/N\). By invoking the spectral theorem we diagonalize \(\vX \vX ^{\top }/N = \vQ \vLambda \vQ ^{\top }\), where \(\vQ \) is orthogonal and \(\vLambda \) is diagonal with non-negative entries. Hence
Since \(\vQ \) is an invertible orthogonal transformation, \(\vQ ^{\top }\tilde {\vu }\) is a unit vector, and optimizing over \(\tilde {\vu }\) is equivalent to optimizing over \(\tilde {\vw } \doteq \vQ ^{\top }\tilde {\vu }\). Hence, we can write
whose optimal solutions \(\vw ^{\star }\) among unit vectors are one-hot vectors whose only nonzero (hence unit) entry is in one of the indices corresponding to the largest eigenvalue of \(\vX \vX ^{\top }/N\). This means that \(\vu ^\star = \vQ \vw ^\star \), the optimal solution to the original problem, corresponds to a unit eigenvector of \(\vX \vX ^{\top }/N\) (i.e., column of \(\vQ \)) which corresponds to the largest eigenvalue. Suitably generalizing this to the case \(d > 1\), and summarizing all the previous discussion, we have the following informal Theorem.
Theorem 2.1. Suppose that our dataset \(\{\vx _{i}\}_{i = 1}^{N} \subseteq \R ^{D}\) can be written as
We do not give explicit rates of approximation here as they can become rather technical. In the special case that \(\veps _{i} = \vzero \) for all \(i\), the learned \(\vU ^{\star }\) spans the support of the samples \(\{\vx _{i}\}_{i = 1}^{N}\). If in addition the \(\vz _{i}\) are sufficiently diverse (say, spanning all of \(\R ^{d}\)) then we would have perfect recovery: \(\vU ^{\star }(\vU ^{\star })^{\top } = \vU \vU ^{\top }\).
Remark 2.1. In some data analysis tasks, the data matrix \(\vX \) is formatted such that each data point is a row rather than a column as is presented here. In this case the principal components are the top \(d\) eigenvectors of \(\vX ^{\top }\vX /N\).
Remark 2.2 (Basis Selection via Denoising Eigenvalues). In many cases, either our data will not truly be distributed according to a subspace-plus-noise model, or we will not know the true underlying dimension \(d\) of the subspace. In this case, we have to choose \(d\); this problem is called model selection. In the restricted case of PCA, one way to perform model selection is to compute \(\vX \vX ^{\top }/N\) and look for instances where adjacent eigenvalues sharply decrease; this is one indicator that the index of the larger eigenvalue is the “true dimension \(d\)”, and the rest of the eigenvalues of \(\vX \vX ^{\top }/N\) are contributed by the noise or disturbances \(\veps _{i}\). Model selection is a difficult problem and, nowadays in the era of deep learning where it is called “hyperparameter optimization”, is usually done via brute force or Bayesian optimization, often using the loss on a holdout (“validation”) dataset as an objective.
Remark 2.3 (Denoising Samples). The expression on the right-hand side of (2.1.5), that is,
Remark 2.4 (Neural Network Interpretation). If we do a PCA, we approximately recover the support of the distribution encoded by the parameter \(\vU ^{\star }\). The learned denoising map then takes the form \(\vU ^{\star }(\vU ^{\star })^{\top }\). On top of being a denoiser, this can be viewed as a simple two-layer weight-tied linear neural network: the first layer multiplies by \((\vU ^{\star })^{\top }\), and the second layer multiplies by \(\vU ^{\star }\), namely
There is a computationally efficient way to estimate the top eigenvectors of \(\vX \vX ^{\top }/N\) or any symmetric positive semidefinite matrix \(\vM \), called power iteration. This method is the building block of several algorithmic approaches to high-dimensional data analysis that we discuss later in the chapter, so we discuss it here.
Let \(\vM \) be a symmetric positive semidefinite matrix. There exists an orthonormal basis for \(\R ^{D}\) consisting of eigenvectors \((\vw _{i})_{i = 1}^{D}\) of \(\vM \), with corresponding eigenvalues \(\lambda _{1} \geq \cdots \geq \lambda _{D} \geq 0\). By definition, any eigenvector \(\vw _i\) satisfies \(\lambda _i \vw _i = \vM \vw _i\). Therefore, for any \(\lambda _i > 0\), \(\vw _i\) is a “fixed point” to the following equation:
Theorem 2.2 (Power Iteration). Assume that \(\lambda _{1} > \lambda _{i}\) for all \(i > 1\). If we compute the fixed point of (2.1.16) using the following iteration:
Proof. First, note that for all \(t\), we have
Remark 2.5 (Power Iteration as a Denoising Process). Notice that computing the principal component via power iteration can be interpreted as a “denoising” process: starting from random noise, it converges iteratively onto a one-dimensional subspace. Indeed, as we will show later in Chapter 3, if we assume the support of the data distribution is a single subspace, the associated denoising operator (or the score function) is precisely the same as the above power iteration. In Chapter 3, we will show how to generalize such a denoising process to distributions of more general low-dimensional structures. This is essentially a universal and most efficient approach to learn any low-dimensional distributions.
To find the second top eigenvector, we apply the power iteration algorithm to \(\vM - \lambda _{1}\vv _{1}\vv _{1}^{\top }\), which has eigenvectors \((\vw _{i})_{i = 2}^{D}\) and corresponding eigenvalues \((\lambda _{i})_{i = 2}^{D}\). By repeating this procedure \(d\) times in sequence, we can very efficiently estimate the top \(d\) eigenvectors of \(\vM \) for any symmetric positive semidefinite matrix \(\vM \). Thus we can also apply it to \(\vX \vX ^{\top }/N\) to recover the top \(d\) principal components, which is what we were after in the first place. Notice that this approach recovers one principal component at a time; we will contrast this to other algorithmic approaches, such as gradient descent on all eigenvectors, in future sections.
Notice that in the above construction, the linear transform \(\vU \) (i.e., the matrix of principal components) used for encoding and decoding is computed “offline” from all the input data beforehand. One question is whether this transform can be learned “online” as the input data comes in order. This question was answered by the work of Oja in 1982 [Oja82].
Example 2.1 (Normalized Hebbian learning scheme for PCA). Consider a sequence of i.i.d. random vectors \(\x _1, \ldots , \x _i, \ldots \in \mathbb {R}^n\) with covariance \(\boldsymbol {\Sigma } \in \mathbb {R}^{n\times n}\). Let \(\vu _0 \in \mathbb {R}^n\) and define the response of an input vector \(\x _i\) against a weight vector \(\vu _i\) to be their inner product:
To interpret the normalized Hebbian scheme (2.1.25), let us think of the data sample PCA objective (2.1.13) as an approximation to the population version of the objective, defined via an expectation over the distribution of samples \(\vx \):
We will dig into this objective further in the following section. Then the normalized Hebbian scheme can be interpreted as a first-order approximation to a stochastic projected gradient descent scheme on Equation (2.1.24) (with batch size \(1\), and with the number of columns of \(\vU \) equal to \(1\)) as long as \(\norm {\vu }_2 = 1\), which is maintained by the projection operation in (2.1.25). Such an online algorithm is a useful primitive for more complex algorithms that process sequentially-structured data with causal structure, as we will study more in Section 5.3.3 and Section 8.11. Interestingly, and more generally, the simple online PCA algorithm is suggestive of the fact that simpler algorithms than (end-to-end) back propagation can succeed in learning encoder-decoder pairs, which we will briefly revisit in Chapter 9 as an important goal for the future study of intelligence.
Notice that the above formulation makes no statistical assumptions on the data-generating process. However, it is common to include statistical elements within a given data model, as it may add further enlightening interpretations about the result of the analysis. As such, we ask the natural question: what is the statistical analogue to low-dimensional structure? Our answer is that a low-dimensional distribution is one whose support is concentrated around a low-dimensional geometric structure.
To illustrate this point, we discuss probabilistic principal component analysis (PPCA) [Row97; TB99]. This formulation can be viewed as a statistical variant of regular PCA. Mathematically, we now consider our data as samples from a random variable \(\vx \) taking values in \(\R ^{D}\) (also sometimes called a random vector). We say that \(\vx \) has (approximate) low-rank statistical structure if and only if there exists an orthonormal matrix \(\vU \in \O (D, d)\), a random variable \(\vz \) taking values in \(\R ^{d}\), and a small random variable \(\veps \) taking values in \(\R ^{D}\) such that \(\vz \) and \(\veps \) are independent, and
Our goal is again to recover \(\vU \). Towards this end, we set up the analogous problem as in Section 2.1.1, i.e., optimizing over subspace supports \(\tilde {\vU }\) and random variables \(\vz \) to solve the following problem:
Since we are finding the best such random variable \(\vz \) we can find its realization \(\vz (\vx )\) separately for each value of \(\vx \). Performing the same calculations as in Section 2.1.1, we obtain
again re-emphasizing the fact that the estimated subspace with principal components \(\vU ^{\star }\) corresponds to a denoiser \(\vU ^{\star }(\vU ^{\star })^{\top }\) which projects onto that subspace. As before, we obtain
and the solution to the latter problem is just the top \(d\) principal components of the second moment matrix \(\Ex [\vx \vx ^{\top }]\). Actually, the above problems are visually very similar to the equations for computing the principal components in the previous subsection, except with \(\Ex [\vx \vx ^{\top }]\) replacing \(\vX \vX ^{\top }/N\). In fact, the latter quantity is an estimate for the former. Both formulations effectively do the same thing, and have the same practical solution—compute the left singular vectors of the data matrix \(\vX \), or equivalently the top eigenvectors of the estimated covariance matrix \(\vX \vX ^{\top }/N\). The statistical formulation, however, has an additional interpretation. Suppose that \(\Ex [\vz ] = \vzero \) and \(\Ex [\veps ] = \vzero \). We have
so that \(\Cov [\vx ] = \Ex [\vx \vx ^{\top }]\). Now working out \(\Cov [\vx ]\) we have
In particular, if \(\Cov [\veps ]\) is small, it holds that \(\Cov [\vx ] = \Ex [\vx \vx ^{\top }]\) is approximately a low-rank matrix, in particular rank \(d\). Thus the top \(d\) eigenvectors of \(\Ex [\vx \vx ^{\top }]\) essentially summarize the whole covariance matrix. But they are also the principal components, so we can interpret principal component analysis as performing a low-rank decomposition of \(\Cov [\vx ]\).
Remark 2.6. By using the probabilistic viewpoint of PCA, we achieve a clearer and more quantitative understanding of how it relates to denoising. First, consider the denoising problem in (2.1.29), namely
Theorem 2.3. Suppose that the random variable \(\vx \) can be written as
In the previous subsections, we discussed the problem of learning a low-rank geometric or statistical distribution, where the data were sampled from a subspace with additive noise. But this is not the only type of disturbance from a low-dimensional distribution that is worthwhile to study. In this subsection, we introduce one more class of non-additive errors which become increasingly important in deep learning. Let us consider the case where we have some data \(\{\vx _{i}\}_{i = 1}^{N}\) generated according to (2.1.1). Now we arrange them into a matrix \(\vX = \mat {\vx _{1}, \dots , \vx _{N}} \in \R ^{D \times N}\). Unlike before, we do not observe \(\vX \) directly; we instead imagine that our observation was corrupted en route and we obtained
where \(\vM \in \{0, 1\}^{D \times N}\) is a mask that is known by us, and \(\hada \) is element-wise multiplication. In this case, our goal is to recover \(\vX \) (from which point we can use PCA to recover \(\vU \), etc), given only the corrupted observation \(\vY \), the mask \(\vM \), and the knowledge that \(\vX \) is (approximately) low-rank. This is called low-rank matrix completion.
This and similar generalizations of this low-rank structure recovery problem are referred to as “Robust PCA” problems. There have been many excellent resources discussing algorithms and approaches to solve these problems [WM22]. Hence we will not go into the solution method here. Instead, we will discuss under what conditions this problem is plausible to solve. On one hand, in the most absurd case, suppose that each entry of the matrix \(\vX \) were chosen independently from all the others. Then there would be no hope of recovering \(\vX \) exactly even if only one entry were missing and we had \(DN - 1\) entries. On the other hand, suppose that we knew that \(\vX \) has rank 1 exactly, which is an extremely strong condition on the low-dimensional structure of the data, and we were dealing with the mask
Then we know that the data are distributed on a line, and we know a vector on that line—it is just the first column of the matrix \(\vY = \vM \hada \vX \). From the last coordinate of each column, also revealed to us by the mask, we can solve for each column since for each final coordinate there is only one vector on the line with this coordinate. Thus we can reconstruct \(\vX \) with perfect accuracy, and we only need a linear number of observations \(D + N - 1\).
In the real world, actual problems are somewhere in between the two limiting cases discussed above. Yet the differences between these two extremes, as well as the earlier discussion of PCA, reveal a general kernel of truth:
The lower-dimensional and more structured the data distribution is, the easier it is to process, and the fewer observations are needed—provided that the algorithm effectively utilizes this low-dimensional structure.
As is perhaps predictable, we will encounter this motif repeatedly in the remainder of the manuscript, starting in the very next section.4
As we have seen, low-rank signal models are rich enough to provide a full picture of the interplay between low-dimensionality in data and efficient and scalable computational algorithms for representation and recovery under errors. These models imply a linear and symmetric representation learning pipeline (2.1.6):
which can be provably learned from finite samples of \(\vx \) with principal component analysis (solved efficiently, say, with the power method) whenever the distribution of \(\vx \) truly is linear. This is a restrictive assumption—for as Harold Hotelling, the distinguished 20th century statistician,5 objected following George Dantzig’s presentation of his theory of linear programming for the first time [Dan02],
“...we all know the world is nonlinear.”
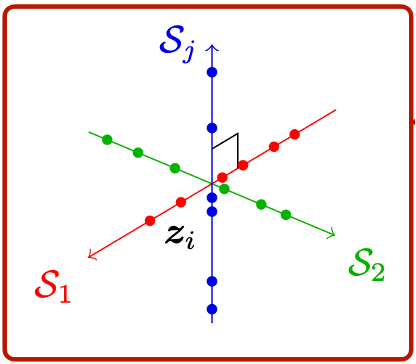
Even accounting for its elegance and simplicity, the low-rank assumption is too restrictive to be broadly applicable to modeling real-world data. A key limitation is the assumption of a single linear subspace that is responsible for generating the structured observations. In many practical applications, structure generated by a mixture of distinct low-dimensional subspaces provides a more realistic model. For example, consider a video sequence that captures the motion of several distinct objects, each subject to its own independent displacement (Figure 2.4 left). Under suitable assumptions on the individual motions, each object becomes responsible for an independent low-dimensional subspace in the concatenated sequence of video frames [VM04]. As another example, consider modeling natural images via learning a model for the distribution of patches, spatially-contiguous collections of pixels, within an image (Figure 2.4 right). Unlike in the simplistic setting of Figure 2.2, where images of faces with matched poses can be well-approximated by a single low-dimensional subspace, the patch at a specific location in a natural image can correspond to objects with very different properties—for example, distinct color or shape due to occlusion boundaries. Therefore, modeling the distribution of patches with a single subspace is futile, but a mixture of subspaces, one for each region, performs surprisingly well in practice, say for segmenting or compressing purposes [MRY+11].6 We will see a concrete example in a later chapter (Example 4.10).
In this section, we will begin by discussing the conceptual and algorithmic foundations for structured representation learning when the data distribution can be modeled by a mixture of low-dimensional subspaces, as illustrated in Figure 2.1. In this setting, the decoder mapping will be almost as simple as the case of a single subspace: we simply represent via
where \(\pi _k : \R ^d \to \set {0,1}\) are a set of sparse weighting random variables, such that only a single subspace \(\mathcal {S}_k = \mathop {\mathrm {col}}(\vU _k) \) is selected in the sum. However, the task of encoding such data \(\vx \) to suitable representations \(\vz \), and learning such an encoder-decoder pair from data, will prove to be more involved.
We will see how ideas from the rich literature on sparse representation and independent component analysis lead to a natural reformulation of the above decoder architecture through the lens of sparsity, the corresponding encoder architecture (obtained through a power-method-like algorithm analogous to that of principal component analysis), and strong guarantees of correctness and efficiency for learning such encoder-decoder pairs from data. In this sense, the case of mixed linear low-dimensional structure already leads to many of the key conceptual components of structured representation learning that we will develop in far greater generality in this book.
Let \(\vU _1, \dots , \vU _K\), each of size \(D \times d\), denote a collection of orthonormal bases for \(K\) subspaces of dimension \(d\) in \(\R ^D\). To say that \(\vx \) follows a mixture-of-subspaces distribution parameterized by \(\vU _1, \dots , \vU _K\) means, geometrically speaking, that
The statistical analogue of this geometric model, as we saw for the case of PCA and linear structure, is that \(\vx \) follows a mixture of Gaussians distribution: that is,
In other words, for each \(k \in [K]\), \(\vx \) is Gaussian on the low-dimensional subspace \(\mathop {\mathrm {col}}(\vU _k)\) with probability \(\pi _k\).
Remark 2.7 (A Mixture of Gaussians v.s. A Superposition of Gaussians). One should be aware that the above model (2.2.3) is a mixture of Gaussian distributions, not to be confused with a mixture of Gaussian variables by superposition, say
For now, we focus on the geometric perspective offered by (2.2.2). There is an algebraically convenient alternative to this conditional representation. Consider a lifted representation vector \(\vz = [\vz _1^\top , \dots , \vz _K^\top ]^\top \in \R ^{dK}\), such that \(\vz \) is \(d\)-sparse with support on one of the \(K\) consecutive non-overlapping blocks of \(d\) coordinates out of \(dK\). Then (2.2.2) can be written equivalently as
Here, the \(\ell ^0\) “norm” \(\norm {\,\cdot \,}_0\) measures sparsity by counting the number of nonzero entries:
and the matrix \(\vU \in \R ^{D \times Kd}\) is called a dictionary with all the \(\{\vU _i\}_{i=1}^K\) as code words. In general, if the number of subspaces in the mixture \(K\) is large enough, there is no bound on the number of columns contained in the dictionary \(\vU \). In the case where \(Kd < D\), \(\vU \) is called undercomplete; when \(Kd = D\), it is called complete; and when \(Kd > D\), it is called overcomplete.
Now, (2.2.5) suggests a convenient relaxation for tractability of analysis: rather than modeling \(\vx \) as coming from a mixture of \(K\) specific subspaces \(\vU _1, \dots , \vU _K\), we may instead start with a dictionary \(\vU \in \R ^{D \times m}\), where \(m\) may be smaller or larger than \(D\), and simply seek to represent \(\vx = \vU \vz \) with the sparsity \(\norm {\vz }_0\) sufficiently small. This leads to the sparse dictionary model for \(\vx \):
where \(\veps \) represents an unknown noise vector. Geometrically, this implies that \(\vx \) lies close to the span of a subset of \(\norm {\vz }_0\) columns of \(\vU \), making this an instantiation of the mixture-of-subspaces model (2.2.2) with a very large value of \(K\), and specific correlations between the subspaces \(\vU _k\).
Orthogonal dictionary for sparse coding. Now we can formulate the structured representation learning problem for mixtures of low-dimensional subspaces that we will study in this section. We assume that we have samples \(\vX = [\vx _1, \dots , \vx _N]\) from an unknown sparse dictionary model (2.2.7), possibly with added noises \(\veps _i\). Let us begin from the assumption that the dictionary \(\vU \) in the sparse dictionary model (2.2.7) is complete and orthogonal,7 and that each coefficient vector \(\vz \) is \(d\)-sparse, with \(d \ll D\). In this setting, representation learning amounts to correctly learning the orthogonal dictionary \(\vU \) via optimization: we can then take \(\cE (\vx ) = \vU ^\top \vx \) as the encoder and \(\cD (\vz ) = \vU \vz \) as the decoder, and \(\cD = \cE ^{-1}\). In diagram form:
We see that the autoencoding pair \((\cE , \cD )\) for complete dictionary learning is symmetric, as in the case of a single linear subspace, making the computational task of encoding and decoding no more difficult than in the linear case. On the other hand, the task of learning the dictionary \(\vU \) is strictly more difficult than learning a single linear subspace by PCA. To see why we cannot simply use PCA to learn the orthogonal dictionary \(\vU \) correctly, note that the loss function that gave rise to PCA, namely (2.1.5), is completely invariant to rotations of the rows of the matrix \(\vU \): that is, if \(\vQ \) is any \(d \times d\) orthogonal matrix, then \(\vU \) and \(\vU \vQ \) are both feasible and have an identical loss for (2.1.5). The sparse dictionary model is decidedly not invariant to such transformations: if we replaced \(\vU \) by \(\vU \vQ \) and made a corresponding rotation \(\vQ ^\top \vz \) of the representation coefficients \(\vz \), we would in general destroy the sparsity structure of \(\vz \), violating the modeling assumption. Thus, we need new algorithms for learning orthogonal dictionaries.
In this section, we will derive algorithms for solving the orthogonal dictionary learning problem. To be more precise, we assume that the observed vector \(\vx \in \R ^D\) follows a statistical model
where \(\vU \in \R ^{D \times D}\) is an unknown orthogonal dictionary, \(\vz \) is a random vector with statistically independent components \(z_i\), each with zero mean, and \(\veps \in \R ^D\) is an independent random vector of small (Gaussian) noises. The goal is to recover \(\vU \) (and hence \(\vz \)) from samples of \(\vx \).
Here we assume that each independent component \(z_i\) is distributed as
That is, it is the product of a Bernoulli random variable with probability \(\theta \) of being \(1\) and \(1-\theta \) of being \(0\), and an independent Gaussian random variable with variance \(1/\theta \). This distribution is formally known as the Bernoulli-Gaussian distribution. The normalization is chosen so that \(\Var (z_i) = 1\) and hence \(\bE [\norm {\vz }_2^2]=d\). This modeling assumption implies that the vector of independent components \(\vz \) is typically very sparse: we calculate \(\bE \left [\norm {\vz }_0\right ] = d\theta \), which is small when \(\theta \) is inversely proportional to \(d\).
Remark 2.8 (The Orthogonal Assumption). At first sight, the assumption that the dictionary \(\vU \) is orthogonal might seem to be somewhat restrictive. But there is actually no loss of generality. One may consider a complete dictionary to be any square invertible matrix \(\vU \). With samples generated from this dictionary: \(\vX = \vU \vZ \in \mathbb {R}^{D\times N}\), it is easy to show that with some preconditioning of the data matrix \(\vX \):
Dictionary learning via the MSP algorithm. Now suppose that we are given a set of observations:
Let \(\vX = [\vx _1, \dots , \vx _N]\) and \(\vZ = [\vz _1, \dots , \vz _N]\). The goal is to recover \(\vU \) from the data \(\vX \). Therefore, given any orthogonal matrix \(\vA \in \O (D)\),
would be nearly sparse if \(\vA = \vU ^\top \) (as by assumption the noise \(\veps _i\) is of small magnitude).
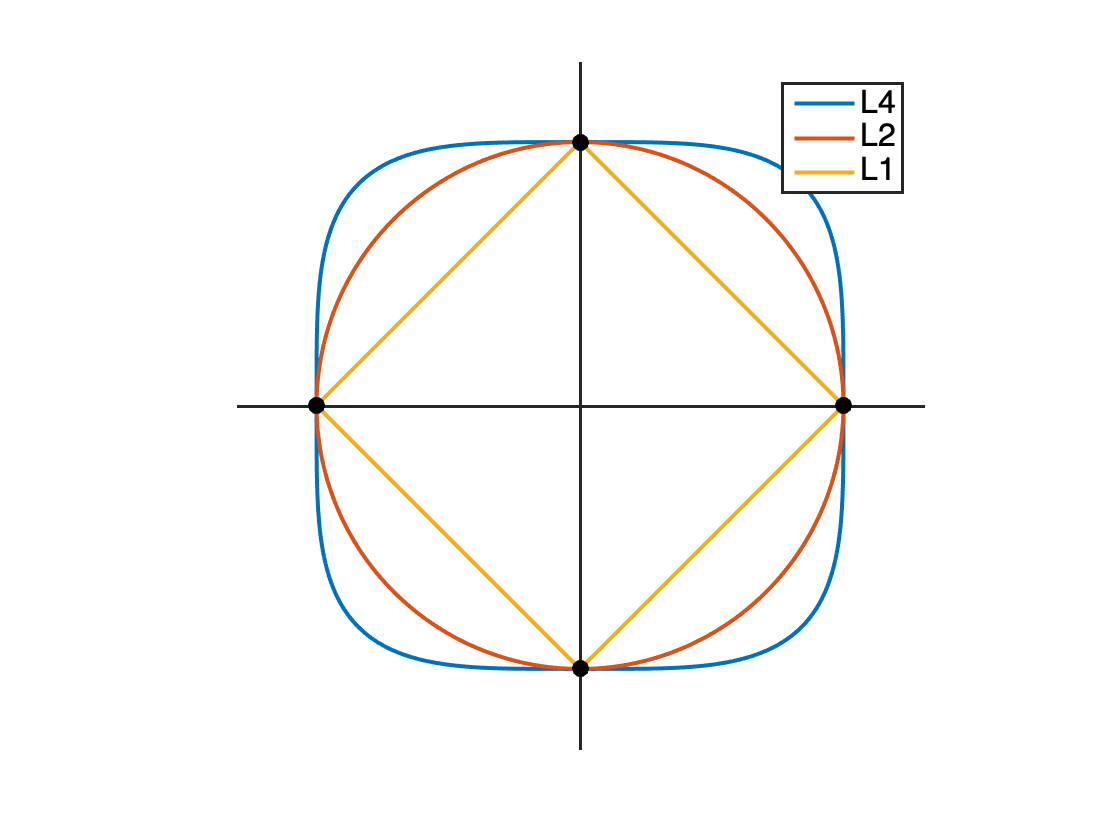
Also, given \(\vU \) is orthogonal and the fact \(\veps \) is small, the vector \(\vx \) has a predictable expected norm, i.e., \(\bE [\norm {\vx }_2^2] \approx \bE [\norm {\vz }_2^2]=d\). It is a known fact that for vectors on a sphere, maximizing the \(\ell ^4\) norm is equivalent to minimizing the \(\ell ^0\) norm (for promoting sparsity),
This is illustrated in Figure 2.5.
An orthogonal matrix \(\vA \) preserves the Euclidean (\(\ell ^{2}\)) norm: \(\|\vA \vx \|_2^2 = \|\vx \|_2^2\). Therefore, to find the correct orthogonal dictionary \(\vU \) from \(\vX \), we may try to solve the following optimization program:
This is known as the \(\ell ^4\) maximization problem [ZMZ+20]. After we find the solution \(\vA ^{\star }\), we can take the transpose \(\vU ^{\star } = (\vA ^{\star })^{\top }\).
Remark 2.9. It is also known that for vectors on a sphere, minimizing the \(\ell ^1\) norm is equivalent to minimizing the \(\ell ^0\) norm (for promoting sparsity),
Note that the above problem is equivalent to the following constrained optimization problem:
As shown in [WM22], using the Lagrange multiplier method, one can derive that the optimal solution to the problem should satisfy the following “fixed point” condition:
where \(\mathcal {P}_{\mathrm O(D)}[\,\cdot \,]\) is a projection onto the space of orthogonal matrices \(\mathrm O(D)\).8
To compute the fixed point for the above equation, similar to how we computed eigenvectors for PCA (2.1.16), we may take the following power iteration:
This is known as the matching, stretching, and projection (MSP) algorithm proposed by [ZMZ+20]. It was shown that under broad conditions such a greedy algorithm indeed converges to the correct solution at a superlinear rate.
Remark 2.10 (Global Optimality of \(\ell ^4\) Maximization). The constrained \(\ell ^4\) maximization problem is a nonconvex program. In general one should not expect that any greedy (say gradient-descent type) algorithms would converge to the globally optimal solution. Surprisingly, one can show that, unlike general nonconvex programs, the landscape of \(\ell ^4\) maximization over a sphere
Remark 2.11 (Stable Deep Linear Network). The above iterative process of computing the dictionary has a natural incremental “deep learning” interpretation. Let us define \(\delta \vA _{t+1} = \tilde {\vA }_{t+1}\tilde {\vA }_{t}^\top \) and \(\vZ _t = \tilde {\vA }_t \vX \), then it is easy to show that
With the Bernoulli-Gaussian model, the variables \(z_i\) are independent and non-Gaussian. Then, there is a clear correspondence between the dictionary learning and the classic independent component analysis (ICA), to the extent that algorithms to solve one problem can be used to solve the other.9
Towards deriving an algorithm based on ICA, we focus on an objective function known as kurtosis, which is used in ICA as a direct consequence of the non-Gaussianity of the components. The kurtosis, or fourth-order cumulant, of a zero-mean random variable \(X\) is defined as
If we have only finite samples from the random variable \(X\) arranged into a vector \(\vx = [x_1, \dots , x_N]\), we define kurtosis through their empirical average, which yields
Finally, for random vectors, we define their kurtosis as the sum of each component’s scalar kurtosis. Kurtosis is a natural loss function for ICA because for Gaussian \(X\), kurtosis is zero; the reader can verify further that the Bernoulli-Gaussian distribution has positive kurtosis. Thus a natural procedure for seeking non-Gaussian independent components is to search for a set of mutually-orthogonal directions \(\tilde {\vU } \in \R ^{d \times k}\), such that \(\tilde {\vU }^\top \vX \) has maximal kurtosis, where \(\vX = \vU \vZ \in \R ^{D \times N}\) is the Bernoulli-Gaussian ICA data matrix (such that \(\tilde {\vU }\) approximates \(\vU \) up to permutations of the columns). Formally, we seek to solve the problem
At one extreme, we may set \(k = D\) and seek to recover the entire dictionary \(\vU \) in a single shot. It can be shown that this problem can be solved with the MSP algorithm we have seen previously. At the other extreme, we may set \(k=1\) and seek to recover a single direction (column of \(\vU \)) at a time, performing deflation, i.e., replacing the data matrix \(\vX \) by \((\vI - \vu \vu ^\top ) \vX \), after each step before finding another direction. There is a natural tradeoff between the scalability of the \(k=1\) incremental approach and the efficiency and robustness of the \(k=D\) approach.
Incremental ICA: correctness and FastICA algorithm. The FastICA algorithm, advanced by Hyvärinen and Oja [HO97], is a fast fixed-point algorithm for solving the \(k=1\) kurtosis maximization scheme for ICA. The problem at hand is
First, we will perform some very basic analysis of this objective to verify its correctness. Notice by the change of variables \(\tilde {\vw } = \vU ^\top \tilde {\vu }\) that this problem is equivalent to
This objective is simple enough that we can make strong statements about its correctness as a formulation for recovering the dictionary \(\vU \). For example, in the population setting where \(N \to \infty \), we may use additivity properties of the kurtosis (Exercise 2.5) and our assumed normalization on the independent components to write the previous problem equivalently as
It can be shown that under the Bernoulli-Gaussian assumption, the optimization landscape of this problem is “benign” (Exercise 2.7)—meaning that all local maxima of the objective function correspond to the recovery of one of the independent components.
In practice, we cannot directly compute the change of variables sending \(\tilde {\vu }\) to \(\tilde {\vw }\) because it requires the ground-truth dictionary \(\vU \), so we develop algorithms directly for the \(\tilde {\vu }\) parameterization and the data matrix \(\vX \). Then one efficient and scalable way to compute one of these maxima is via first-order optimization algorithms, which iteratively follow the gradient of the objective function and project onto the constraint set \(\set {\tilde {\vu } \given \norm {\tilde {\vu }}_2^2 = 1}\). Since we have assumed that each \(z_i\) satisfies \(\Var (z_i)=1\), we have for any \(\tilde {\vu }\), for large enough \(N\)
We can then derive a corresponding approximation to the gradient:
The FastICA algorithm uses a fixed-point method to compute directions of maximum kurtosis. It starts from the first-order optimality conditions for the kurtosis maximization problem, given the preceding gradient approximation and the constraint set, which read
where the specific value of \(\lambda \) is determined using the unit norm constraint on \(\tilde {\vu }\). Exercise 2.6 describes the mathematical background necessary to derive these optimality conditions from first principles. Equation (2.2.26) is satisfied by any critical point of the kurtosis maximization problem; we want to derive an equation satisfied by only the maximizers. After noticing that \(\lambda = \norm {\vX ^\top \tilde {\vu }}_4^4\), we equivalently re-express (2.2.26) as the modified equation
and realize that any maximizer of (2.2.23) must satisfy \(\lambda / N - 3 > 0\), assuming that \(N\) is sufficiently large. Hence, we may normalize both sides of (2.2.27), giving the following fixed-point equation satisfied by every maximizer of (2.2.23):
Iterating the mapping defined by the lefthand side of this fixed point expression then yields the FastICA algorithm of Hyvärinen and Oja [HO97]:
It turns out that the FastICA algorithm converges extremely rapidly (actually at a cubic rate) to columns of the dictionary \(\vU \); interested readers may consult [HO97] for details. Comparing the FastICA algorithm (2.2.29) to the power method studied in Section 2.1.1 for the PCA problem and the MSP algorithm (2.2.18), we notice a striking similarity. Indeed, FastICA is essentially a modified power method, involving the gradient of the empirical kurtosis rather than the simpler linear gradient of the PCA objective.
As we have seen, complete dictionary learning enjoys an elegant computational theory in which we maintain a symmetric autoencoding structure \(\cE (\vx ) = \vU ^\top \vx \), \(\cD (\vz ) = \vU \vz \), with a scalable power-method-like algorithm (the MSP algorithm) for learning an orthogonal dictionary/codebook \(\vU \) from data. Nevertheless, for learning representations of general high-dimensional data distributions, one must expand the size of the codebook beyond the orthogonality requirement—meaning that we must have \(\vA \in \R ^{D \times m}\), with \(m \gg D\), corresponding to the case of an overcomplete dictionary/codebook,10 and the signal model
There are both geometric and physical/modeling motivations for passing to the overcomplete case. Geometrically, recall that in our original reduction from the mixture of subspace data model to the sparse dictionary model, a mixture of \(K\) subspaces in \(\R ^D\), each of dimension \(d\), led to a dictionary of shape \(\vA \in \R ^{D \times Kd}\). In other words, overcomplete dictionaries correspond to richer mixtures of subspaces, with more distinct modes of variability for modeling the high-dimensional data distribution. On the modeling side, we may run a computational experiment on real-world data that reveals the additional modeling power conferred by an overcomplete representation.
Example 2.2. Given sampled images of hand-written digits, Figure 2.6(a) shows the result of fitting an orthogonal dictionary to the dataset. In contrast, Figure 2.6(b) shows the result of running an optimization algorithm for learning overcomplete dictionaries (which we will present in detail later in the Chapter) on these samples. Notice that the representations become far sparser and the codebooks far more interpretable—they consist of fundamental primitives for the strokes composing the digits, i.e. oriented edges. \(\blacksquare \)
In fact, overcomplete dictionary learning was originally proposed as a biologically plausible algorithm for image representation based on empirical evidence of how early stages of the visual cortex represent visual stimuli [OF97; OF96].
In the remainder of this section, we will overview the conceptual and computational foundations of overcomplete dictionary learning. Supposing that the model (2.3.1) is satisfied with sparse codes \(\vz \), overcomplete dictionary \(\vA \), and sparsity level \(d\), and given samples \(\vX = [\vx _1, \dots , \vx _N]\) of \(\vx \), we want to learn an encoder \(\cE : \R ^D \to \R ^m\) mapping each \(\vx \) to its sparse code \(\vz \), and a decoder \(\cD (\vz ) = \vA \vz \) reconstructing each \(\vx \) from its sparse code. In diagram form:
We will start from the construction of the encoder \(\cE \). We will work incrementally: first, given the true dictionary \(\vA \), we will show how the problem of sparse coding gives an elegant, scalable, and provably-correct algorithm for recovering the sparse code \(\vz \) of \(\vx \). Although this problem is NP-hard in the worst case, it can be solved efficiently and scalably for dictionaries \(\vA \) which are incoherent, i.e. having columns that are not too correlated. The encoder architecture encompassed by this solution will no longer be symmetric: we will see it has the form of a primitive deep network, which depends on the dictionary \(\vA \).
Then we will proceed to the task of learning the decoder \(\cD \), or equivalently the overcomplete dictionary \(\vA \). We will derive an algorithm for overcomplete dictionary learning that allows us to simultaneously learn the codebook \(\vA \) and the sparse codes \(\vz \), using ideas from sparse coding. Finally, we will discuss a more modern perspective on learnable sparse coding that leads us to a fully asymmetric encoder-decoder structure, as an alternative to (2.3.2). Here, the decoder will correspond to an incremental solution to the sparse dictionary learning problem, and yield a pair of deep network-like encoder decoders for sparse dictionary learning. This structure will foreshadow many developments to come in the remainder of the monograph, as we progress from analytical models to modern neural networks.
In this section, we will consider the data model (2.3.1), which accommodates sparse linear combinations of many motifs, or atoms. Given data \(\{\vx _{i}\}_{i = 1}^{N} \subseteq \R ^{D}\) satisfying this model, i.e. expressible as
for some dictionary \(\vA \in \bR ^{D \times m}\) with \(m\) atoms, sparse codes \(\vz _i\) such that \(\norm {\vz _i}_0 \leq d\), and small errors \(\veps _i\), the sparse coding problem is to recover the codes \(\vz _i\) as accurately as possible from the data \(\vx _i\), given the dictionary \(\vA \). Efficient algorithms to solve this problem succeed when the dictionary \(\vA \) is incoherent in the sense that the inner products \(\va _{i}^{\top }\va _{j}\) are uniformly small, hence the atoms are nearly orthogonal.11
Note that we can collect the \(\vx _{i}\) into \(\vX = \mat {\vx _{1}, \dots , \vx _{N}} \in \R ^{D \times N}\), collect the \(\vz _{i}\) into \(\vZ = \mat {\vz _{1}, \dots , \vz _{N}} \in \R ^{d \times N}\), and collect the \(\veps _{i}\) into \(\vE = \mat {\veps _{1}, \dots , \veps _{N}} \in \R ^{D \times N}\), to rewrite (2.3.3) as
A natural approach to solving the sparse coding problem is to seek the sparsest signals that are consistent with our observations, and this naturally leads to the following optimization problem:
where the \(\ell ^1\) norm \(\norm {\tilde {\vZ }}_{1}\), taken elementwise, is known to promote sparsity of the solution [WM22]. This optimization problem is known as the LASSO problem.
However, unlike PCA or the complete dictionary learning problem, there is no clear power iteration-type algorithm to compute the optimal \(\vZ ^{\star }\). A natural alternative is to consider solving the above optimization problem with gradient descent type algorithms. Let \(\cL (\tilde {\vZ }) = \norm {\vX - \vA \tilde {\vZ }}_{2}^{2} + \lambda \norm {\tilde {\vZ }}_{1}\). Conceptually, we could try to compute \(\vZ ^{\star }\) with the following iterations:
However, because the term associated with the \(\ell ^1\) norm \(\norm {\tilde {\vZ }}_{1}\) is non-smooth, we cannot just run gradient descent. For this type of function, we need to replace the gradient \(\nabla \cL (\tilde {\vZ })\) with something that generalizes the notion of gradient, known as the subgradient \(\partial \cL (\tilde {\vZ })\):
However, it is known that the convergence of subgradient descent is usually very slow. Hence, for this type of optimization problems, it is conventional to adopt a so-called proximal gradient descent-type algorithm. We give a technical overview of this method in Section A.1.3.
Applying proximal gradient to the LASSO objective function (2.3.5) leads to the classic iterative shrinkage-thresholding algorithm (ISTA), which implements the iteration
with step size \(\eta \geq 0\), and the soft-thresholding operator \(S_{\alpha }\) defined on scalars by
and applied element-wise to the input matrix. As a proximal gradient descent algorithm applied to a convex problem, convergence to a global optimum is assured, and a precise convergence rate can be derived straightforwardly [WM22].
We now take a moment to remark on the functional form of the update operator in (2.3.9). It takes the form
This functional form is very similar to that of a residual network layer, namely,
only decoupling the linear maps (i.e., matrix multiplications), adding a bias, and moving the nonlinearity. The nonlinearity in (2.3.9) is notably similar to the commonly-used ReLU activation function \(x \mapsto \max \set {x, 0}\) in deep learning—as visualized in Figure 2.7, the soft-thresholding operator is like a “signed” ReLU activation, which is also shifted by a bias. The ISTA, then, can be viewed as a forward pass of a primitive (recurrent one-layer) neural network. We argue in Chapter 5 that such operations are essential to deep representation learning.
Recall that we have the data model
where \(\vZ \) is sparse, and our goal previously was to estimate \(\vZ \) given knowledge of the data \(\vX \) and the dictionary atoms \(\vA \). Now we turn to the more practical and more difficult case where we do not know either \(\vA \) or \(\vZ \) and seek to learn them from a large dataset.
A direct generalization of Equation (2.3.5) suggests solving the problem
However, the bilinear term in Equation (2.3.12) introduces a scale ambiguity that hinders convergence: given any point \((\tilde {\vA }, \tilde {\vZ })\) and any constant \(c>0\), the substitution \((c^{-1}\tilde {\vA }, c\tilde {\vZ })\) gives loss value
This loss is evidently minimized over \(c\) by taking \(c \to 0\), which corresponds to making the rescaled dictionary \(c^{-1} \tilde {\vA }\) go ‘to infinity’. In particular, the iterates of any optimization algorithm solving (2.3.15) will not converge.
This issue with (2.3.15) is dealt with by adding a constraint on the scale of the columns of the dictionary \(\tilde {\vA }\). For example, it is common to assume that each column \(\vA _j\) of the dictionary \(\vA \) in (2.3.14) has bounded \(\ell ^2\) norm—say, without loss of generality, by \(1\). We then enforce this as a constraint, giving the objective
Constrained optimization problems such as (2.3.17) can be solved by a host of sophisticated algorithms [NW06]. However, a simple and scalable one is actually furnished by the same proximal gradient descent algorithm that we used to solve the sparse coding problem in the previous section. We can encode each constraint as additional regularization term, via the characteristic function for the constraint set—details are given in Example A.1. Applying proximal gradient descent to the resulting regularized problem is equivalent to projected gradient descent, in which, at each iteration, the iterates after taking a gradient descent step are projected onto the constraint set.
Remark 2.12 (\(\ell ^4\) maximization versus \(\ell ^1\) minimization). Note that the above problem formulation follows naturally from the LASSO formulation (2.3.5) for sparse coding. We promote the sparsity of the solution via the \(\ell ^1\) norm. Nevertheless, if we are only interested in recovering the over-complete dictionary \(\vA \), the \(\ell ^4\) maximization scheme introduced in Section 2.2.2 also generalizes to the over-complete case, without any significant modification. Interested readers may refer to the work of [QZL+20a].
The above problem (2.3.17), which we call overcomplete dictionary learning, is nonconvex as here both \(\vA \) and \(\vZ \) are unknown. It cannot be solved easily by the standard convex optimization toolkit. Nevertheless, because it is interesting, simple to state, and practically important, there have been many important works dedicated to different algorithms and theoretical analysis for this problem. Here, for the interest of this manuscript, we present an idiomatic approach to solve this problem which is closer to the spirit of deep learning.
From our experience with the LASSO problem above, it is easy to see that, for the two unknowns \(\vA \) and \(\vZ \), if we fix one and optimize the other, each subproblem is in fact convex and easy to solve. This naturally suggests that we could attempt to solve the above program (2.3.17) by minimizing against \(\vZ \) or \(\vA \) alternatively, say using gradient descent. Coupled with a natural choice of initialization, this leads to the following iterative scheme:
where the projection operation in the update for \(\vA \) ensures each column has at most unit \(\ell ^2\) norm, via \(\vA _j \mapsto \vA _j / \max \set {\norm {\vA _j}_2, 1}\), and where \(\vA _+\) is initialized with each column i.i.d. \(\cN (\Zero , \tfrac {1}{D} \vI )\). The above consists of one ‘block’ of alternating minimization, and we repeatedly perform such blocks, each with independent initializations, until convergence. Above, we have used two separate indices \(\{t\}\) and \(\{\ell \}\) to indicate the iterations. As we will see later, this allows us to interpret the two updates separately in the context of deep learning.
Despite the dictionary learning problem being a nonconvex problem, it has been shown that alternating minimization type algorithms indeed converge to the correct solution, at least locally. See, for example, [AAJ+16]. As a practical demonstration, the above algorithm (with \(L = T = 1\)) was used to generate the results for overcomplete dictionary learning in Figure 2.6.
The main insight from the alternating minimization algorithm for overcomplete dictionary learning in the previous section (Equation (2.3.15) and 2.3.20) is to notice that when we fix \(\vA \), the ISTA update for \(\vZ ^\ell \) (2.3.18) looks like the forward pass of a deep neural network with weights given by \(\vA \) (and \(\vA ^{\top }\)). But in general, we do not know the true \(\vA \), and the current estimate \(\vA _+\) could be erroneous. Hence it needs to be further updated using (2.3.20) based on the residual of using the current estimate of the sparse codes \(\vZ ^+\) to reconstruct \(\vX \). The alternating minimization algorithm iterates these two procedures until convergence. But we can instead extrapolate, and design other learning procedures by combining these insights with techniques from deep learning. This leads to more interpretable network architectures, which will be a recurring theme throughout this manuscript.
Learned ISTA. The above deep-network interpretation of the alternating minimization is more conceptual than practical, as the process could be rather inefficient and take many layers or iterations to converge. But this is mainly because we try to infer both \(\vZ \) and \(\vA \) from \(\vX \). The problem can be significantly simplified and the above iterations can be made much more efficient in the supervised setting, where we have a dataset of input and output pairs \((\vX , \vZ )\) distributed according to (2.3.14) and we only seek to learn \(\vA ^\ell \) for the layerwise learnable sparse coding iterations (2.3.29):12
If we denote the operator for each iteration as \(\vZ ^{\ell + 1} = f(\vA ^\ell , \vZ ^\ell )\), the above iteration can be illustrated in terms of a diagram:
Thus, given the sequential architecture, to learn the operator \(\vA ^\ell \) at each layer, it is completely natural to learn it, say via back propagation (BP),13 by minimizing the error between the final code \(\vZ ^L\) and the ground truth \(\vZ \):
This is the basis of the Learned ISTA (LISTA) algorithm [GL10], which can be viewed as the learning algorithm for a deep neural network, which tries to emulate the sparse encoding process from \(\vX \) to \(\vZ \). In particular, it can be viewed as a simple representation learning algorithm. In fact, this same methodology can be used as a basis to understand the representations computed in more powerful network architectures, such as transformers. We develop these implications in detail in Chapter 5.
Sparse Autoencoders. The original motivation for overcomplete dictionary learning was to provide a simple generative model for high-dimensional data. We have seen with LISTA that, in addition, iterative algorithms for learning sparsely-used overcomplete dictionaries provide an interpretation for ReLU-like deep networks, which we will generalize in later chapters to more complex data distributions than (2.3.14). But it is also worth noting that even in the modern era of large models, the data generating model (2.3.14) provides a useful practical basis for interpreting features in pretrained large-scale deep networks, such as transformers, following the hypothesis that the (non-interpretable, a priori) features in these networks consist of sparse “superpositions” of underlying features, which are themselves interpretable [EHO+22b]. These unsupervised learning paradigms are generally more data friendly than LISTA, as well, which requires large amounts of labeled \((\vX , \vZ )\) pairs for supervised training.
We can use our development of the LISTA algorithm above to understand common practices in this field of research. In the most straightforward instantiation (see [GTT+25; HCS+24]), a large number of features from a pretrained deep network \(h\) are collected from different inputs \(\vx _i\), which themselves are chosen based on a desired interpretation task.14 For simplicity, we will use \(h\) to denote the pre-selected feature map in question, with \(D\)-dimensional features; given \(N\) sample inputs, let \(\vH \in \bR ^{D \times N}\) denote the full matrix of features of \(h\). Then a so-called sparse autoencoder \(f : \bR ^D \to \bR ^d\), with decoder \(g : \bR ^d \to \bR ^D\), is trained via the LASSO loss (2.3.5):
where the sparse autoencoder \(f\) takes the form of a one-layer neural network, i.e. \(f(\vh _i) = \sigma (\vW _{\mathrm {enc}}(\vh _i - \vb ) + \vb _{\mathrm {enc}})\), where \(\sigma (x) = \max \{x, 0\}\) is the ReLU activation function, and the decoder \(g\) is linear, so that \(g(\vz _i) = \vW _{\mathrm {dec}}\vz + \vb \).15
The parameterization and training procedure (2.3.24) may initially seem to be an arbitrary application of deep learning to the sparse coding problem, but it is actually highly aligned with the algorithms we have studied above for layerwise sparse coding with a learned dictionary. In particular, recall the LISTA architecture \(\vZ ^{L} = f(\vA ^L, f(\vA ^{L-1}, \cdots , f(\vA ^1, \vX ) \cdots ))\). In the special case \(L=2\), we have
Let us assume that the sparse codes \(\vZ \) in question are nonnegative, i.e., that \(\vZ \geq \Zero \).16 Then (see Example A.3), we can consider an equivalent LISTA architecture obtained from the sparse coding objective with an additional nonnegativity constraint on \(\vZ \) as
and after some algebra, express this as
Given the ability to change the sparse code initialization \(\vZ ^1\) as a learnable parameter (which, in the current framework, must have all columns equal to the same learnable vector), this has the form of a ReLU neural network with learnable bias—identical to the sparse autoencoder \(f\)! Moreover, to decode the learned sparse codes \(\vZ ^2\), it is natural to apply the learned dictionary \(\vZ ^2 \mapsto \vA ^1 \vZ ^2\). Then the only difference between this and the SAE decoder \(g\) is the additional bias \(\vb \), which can technically be absorbed into \(\vH \) and \(f\) in the training objective (2.3.24).
Thus, the SAE parameterization and training procedure coincides with LISTA training with \(L=1\), and a modified training objective—using the LASSO objective (2.3.5), which remains unsupervised, instead of the supervised reconstruction loss (2.3.23) used in vanilla LISTA. In particular, we can understand the SAE architecture in terms of our interpretation of the LISTA architecture in terms of layerwise sparse coding in (2.3.29). This connection is suggestive of a host of new design strategies for improving practical interpretability methodology, many of which remain tantalizingly unexplored. We begin to lay out some connections to broader autoencoding methodology in Chapter 6.
Layerwise learned sparse coding? In the supervised setting, LISTA provides a deep neural network analogue of the sparse coding iteration, with layerwise-learned dictionaries, inspired by alternating minimization; even in the unsupervised setting, the same methodology can be applied to learning, as with sparse autoencoders. But the connection between low-dimensional-structure-seeking optimization algorithms and deep network architectures goes much deeper than this, and suggests an array of scalable and natural neural learning architectures which may even be usable without backpropagation.
As a simple illustration, we return the alternating minimization iterations (2.3.18) and (2.3.20). This scheme randomly re-initializes the dictionary \(\vA _1\) on every such update. An improvement uses instead warm starting, where the residual is generated using the previous estimate \(\vA _+\) for the dictionary. If we then view each ISTA update (2.3.18) as a layer and allow the associated dictionary, now coupled with the sparse code updates as \(\vA _\ell \), to update in time, this leads to a “layerwise-learnable” sparse coding scheme:
Note that this iteration corresponds to a relabeling of (2.3.18) and (2.3.20) for \(T = L = 1\), over infinitely many blocks. Each of the ‘inner’ steps updating \(\vZ \) can be considered as a one-layer forward pass, while each of the ‘outer’ steps updating \(\vA \) can be considered as a one-layer backward pass, of a primitive deep neural network. In particular, this algorithm is the simplest case in which a clear divide between forward optimization and backward learning manifests. This distinction between forward updates to the ephemeral “features” \(\vZ \) of data \(\vX \) versus backward updates to the persistent parameters \(\vA \) is still observed in current neural networks and autoencoders—we will have much more to say about it in Chapter 5 and in Chapter 6.
Notice that the above layer-wise scheme also suggests a plausible alternative to the current end-to-end optimization strategy that primarily relies on back propagation (BP) detailed in Section A.2.3. Freeing training large networks from BP would be one of the biggest challenges and opportunities in the future, as we will discuss more at the end of the book in Chapter 9.
Key Messages. The idealistic models we have presented in this chapter—PCA, ICA, and dictionary learning—were developed over the course of the twentieth century. Many books have been written solely about each method, so we only attempted here to give a broad overview of the key concepts and results. As we will see in coming chapters, although these are arguably rather idealistic simple models for low-dimensional data distributions, the basic ideas and even resulting algorithms to identify such distributions can be naturally generalized or extended to arbitrary low-dimensional distributions – the thesis of this book. In addition, as we will see in coming chapters, these basic (linear) models, to a large extent, can also serve as local prototypes to effectively approximately model general distributions with nonlinear low-dimensional structures.
More History and References. Jolliffe [Jol86] attributes principal component analysis to Pearson [Pea01], and independently Hotelling [Hot33]. In mathematics, the main result on the related problem of low-rank approximation in unitarily invariant norms is attributed to Eckart and Young [EY36], and to Mirsky for full generality [Mir60]. PCA continues to play an important role in research as perhaps the simplest model problem for unsupervised representation learning: as early as the 1980s, works such as Oja [Oja82] and Baldi and Hornik [BH89] used the problem to understand learning in primitive neural networks, and more recently, it has served as a tool for understanding more complex representation learning frameworks, such as diffusion models [WZZ+24].
Independent component analysis was proposed by B. Ans et al. [BJC85] and pioneered by Aapo Hyvärinen in the 1990s and early 2000s in a series of influential works: see Hyvärinen and Oja [HO00b] for a summary. As a simple model for structure that arises in practical data, it initially saw significant use in applications such as blind source separation, where each independent component \(z_i\) represents an independent source (such as sound associated to a distinct instrument in a musical recording) that is superimposed to produce the observation \(\vx = \vU \vz \).
The problem of dictionary learning can, in the complete or orthogonal case, be seen as one of the foundational problems of twentieth-century signal processing, particularly in linear systems theory, where the Fourier basis plays the key role; from the 1980s onward, the field of computational harmonic analysis crystallized around the study of alternate such dictionaries for classes of signals in which optimal approximation could only be realized in a basis other than Fourier (e.g., wavelets) [DVD+98]. However, the importance of the case of redundant bases, or overcomplete dictionaries, was only highlighted following the pioneering work of Olshausen and Field [OF97; OF96]. Early subsequent work established the conceptual and algorithmic foundations for learning sparsely-used overcomplete dictionaries, often aimed at representing natural images [AEB06; DM03; Don01; EA06; GJB15; MBP14; MK07]. Later, a significant amount of theoretical interest in the problem, as an important and nontrivial model problem for unsupervised representation learning, led to its study by the signal processing, theoretical machine learning, and theoretical computer science communities, in particular focused on conditions under which the problem could be provably and efficiently solved. A non-exhaustive list of notable works in this line include those of Spielman et al. [SWW12] and Sun et al. [SQW17a] on the complete case; Arora et al. [AGM+15]; Barak et al. [BKS15]; and Qu et al. [QZL+20a]. Many deep theoretical questions about this simple-to-state problem remain open, perhaps in part due to a tension with the problem’s worst-case NP-hardness (e.g., see Tillmann [Til15]).
| Problem | Algorithm | Iteration | Type of Structure Enforced |
| PCA | Power Method | \(\vu _{t} = \frac {\vX \vX ^\top \vu _{t}}{\norm {\vX \vX ^\top \vu _{t}}_2}\) | \(1\)-dim. subspace (unit vector) |
| ICA | FastICA | \(\vu _{t+1} = \frac {\tfrac {1}{N}\vX (\vX ^\top \vu _{t})^{\hada 3}- 3 \vu _{t}}{\left\Vert \tfrac {1}{N}\vX (\vX ^\top \vu _{t})^{\hada 3}- 3 \vu _{t}\right\Vert_2}\) | \(1\)-dim. subspace (unit vector) |
| Complete DL | MSP Algorithm | \(\vU _{t+1} = \mathcal {P}_{\mathrm O(D)}[( {\vU _t \vX })^{\hada 3}\vX ^\top ]\) | \(D\)-dim. subspace (ortho. matrix) |
One point that we wish to highlight from the study of these classical analytical models for low-dimensional structure is the common role played by various generalized power methods—algorithms that very rapidly converge, at least locally, to various types of low-dimensional structures. The terminology for this class of algorithms follows the work of M. Journée et al. [MYP+10]. At a high level, modeled on the classical power iteration for computation of the top eigenvector of a semidefinite matrix \(\vA \in \bR ^{n \times n}\), that is
this class of algorithms consists of a “powering” operation involving a matrix \(\vA \) associated to the data, along with a “projection” operation that enforces a desired type of structure. Table 2.1 presents a summary of the algorithms we have studied in this chapter that follow this structure. The reader may appreciate the applicability of this methodology to different types of low-dimensional structure, and different losses (i.e., both the quadratic loss from PCA, and the kurtosis-type losses from ICA), as well as the lack of such an algorithm for overcomplete dictionary learning, despite the breadth of the literature on these algorithms. We see the development of power methods for further families of low-dimensional structures, particularly those relevant to applications where deep learning is prevalent, as one of the more important (and open) research questions suggested by this chapter.
The connection we make in Section 2.2.1 between the geometric mixture-of-subspaces distributional assumption and the more analytically-convenient sparse dictionary assumption has been mentioned in prior work, especially by those focused on generalized principal component analysis and applications such as subspace clustering, e.g., work of Vidal et al. [VMS16]. The mixture of subspaces assumption will continue to play a significant role throughout this manuscript, both as an analytical test case for different algorithmic paradigms, and as a foundation for deriving different deep network architectures, as with LISTA in Section 2.3.3, but which can scale to more complex data distributions.
Exercise 2.1. Prove that, for any symmetric matrix \(\vA \), the solution to the problem \(\max _{\vU \in \O (D, d)}\tr \left (\vU ^{\top }\vA \vU \right )\) is the matrix \(\vU ^{\star }\) whose columns are the top \(d\) unit eigenvectors of \(\vA \).
Exercise 2.2. Let \(\vz \sim \cN (\Zero , \sigma ^2 \vI )\) be a Gaussian random variable with independent components, each with variance \(\sigma ^2\). Prove that for any orthogonal matrix \(\vQ \) (i.e., \(\vQ ^\top \vQ = \vI \)), the random variable \(\vQ \vz \) is distributed identically to \(\vz \). (Hint: recall the formula for the Gaussian probability density function, and the formula for the density of a linear function of a random variable.)
Exercise 2.3. The notion of statistical identifiability discussed above can be related to symmetries of the model class, allowing estimation to be understood in a purely deterministic fashion without any statistical assumptions.
Consider the model \(\vX = \vU \vZ \) for matrices \(\vX , \vU , \vZ \) of compatible sizes.
Exercise 2.4. Consider the model \(\vx = \vU \vz \), where \(\vU \in \R ^{D \times d}\) with \(D \geq d\) is fixed and has rank \(d\), and \(\vz \) is a zero-mean random variable. Let \(\vx _1, \dots , \vx _N\) denote i.i.d. observations from this model.
Exercise 2.5. Let \(X\) and \(Y\) be zero-mean independent random variables.
Exercise 2.6. Let \(f : \R ^d \to \R \) be a given twice-continuously-differentiable objective function. Consider the spherically-constrained optimization problem
Exercise 2.7. In this exercise, we sketch an argument referred to in the literature as a landscape analysis for the spherically-constrained population kurtosis maximization problem (2.2.24). We will show that when there is at least one independent component with positive kurtosis, its global maximizers indeed lead to the recovery of one column of the dictionary \(\vU \). For simplicity, we will assume that \(\kurt (z_i) \neq 0\) for each \(i = 1, \dots , d\).
Exercise 2.8. This exercise follows the structure and formalism introduced in Exercise 2.6, but applies it instead to the orthogonal group \(\O (d) = \set {\vU \in \R ^{d \times d} \given \vU ^\top \vU = \vI }\). Consult the description of Exercise 2.6 for the necessary conceptual background; the formalism applies identically to the case where the ambient space is the set of \(d \times d\) matrices as long as one recalls that the relevant inner product on matrices is \(\ip {\vX }{\vY } = \tr (\vX ^\top \vY )\). An excellent general reference for facts about optimization on the orthogonal group is Edelman, Arias, and Smith [EAS98].
Let \(f : \R ^{d\times d} \to \R \) be a given twice-continuously-differentiable objective function. Consider the orthogonally-constrained optimization problem
(Hint: The key is to manipulate one’s calculations to obtain the form (2.5.8), which is as compact as possible. To this end, make use of the following isomorphism of the Kronecker product: if \(\vA \), \(\vX \), and \(\vB \) are matrices of compatible sizes, then one has
(Hint: use linearity of the Kronecker product in either of its two arguments when the other is fixed.)



![[Picture]](book-main1x.svg)




![[Picture]](book-main2x.svg)