“What I cannot create, I do not understand.”
\(~\) — Richard Feynman
In previous chapters, we have shown how to identify low-dimensional structures in high-dimensional spaces, mainly focusing on linear structures. For example, we introduced principal component analysis (PCA) to learn the linear denoiser \(\hat {\bm {U}}^{\top }\) when the observed data \(\bm {x}\) follow the statistical model \(\bm {x} = \bm {U}\bm {z} + \bm {\varepsilon }\). In this setting, the learned representations are linearly transformed input data \(\hat {\bm {U}}^{\top }\bm {x}\). Under the linear model assumption, one can learn the low-dimensional linear structure with efficient optimization algorithms and strong theoretical guarantees. Moreover, the linear model assumption covers a wide range of applications and problems, including face recognition, magnetic resonance image recovery, and structure texture recovery [WM22].
On the other hand, the linear model can be limited when dealing with real-world applications, especially when the input data \(\bm {x}\) is complex, such as speech and natural languages, images and videos, and robotic motions. The low-dim distributions of such data are typically nonlinear. How to deal with nonlinearity has a long history across different disciplines such as control theory, signal processing, and pattern recognition. There have been considerable efforts that try to extend methods and solutions for linear models to handle nonlinearity, including early effort to extend PCA to nonlinear PCA (as we will study in more detail in Chapter 6). In most cases, the methods are designed based on certain assumptions about the data distributions and tailored to specific problems.
More recently, deep neural networks have achieved remarkable success across a wide range of data and applications. A neural network
can learn effective features/representations for downstream applications. For example, a trained deep neural network \(f(\cdot , \bm \theta )\) can be applied to map images to feature vectors, that is, \(\bm {z}_i = f(\bm {x}_i,\bm \theta )\), while a linear classifier can be learned on top of such representations \(\{\bm {z}_i\}\). One notable breakthrough is AlexNet [KSH12], a deep convolutional neural network trained with more than a million natural images, outperforming (on predictive tasks) all previous approaches that were based on hand-crafted features. One of the key differences between AlexNet and previous approaches is that the former learns parameters of the nonlinear transformation from massive amounts of data trained with back-propagation (BP) [RHW86b], as detailed in Section A.2.3 of Chapter A.
Subsequent popular practice models the mapping \(f\) with other empirically designed artificial deep neural networks and learns the parameters \(\bm \theta \) from random initialization via BP. Starting with the AlexNet [KSH12], the architectures of modern deep networks continue to be empirically revised and improved. Network architectures such as VGG [SZ14], ResNet [HZR+16b], DenseNet [HLV+17], CNN, RNN or LSTM [HS97], Transformer [VSP+17b], and mixtures of experts (MoE) [FZS22; SMM+17], etc. have continued to push the performance envelope. As part of the effort to improve the performance of deep networks, almost every component of the networks has been empirically scrutinized, and various revisions and improvements have been proposed. They are not limited to nonlinear activation functions [KUM+17; MHN13; NIG+18; XWC+15], skip connections [HZR+16b; RFB15b], normalizations [BKH16; IS15; MKK+18; UVL16; WH20], up/down sampling or pooling [SMB10], convolutions [KSH12; LBB+98b], etc. However, almost all such modifications have been developed through years of empirical trial and error or ablation studies. Some recent practices even take to the extreme by searching for effective network structures and training strategies through extensive random search techniques, such as Neural Architecture Search [BGN+17; ZL17], AutoML [HKV19], and Learning to Learn [ADG+16].
Despite the wide application of deep neural networks, it is not clear what the underlying design principles of such a constructed network are. In particular, it is not clear what mathematical function each layer of the network performs. In this chapter, based on the results from previous chapters, we develop a principled framework that will provide a fully rigorous mathematical interpretation of the role of a deep network, including its individual layers and the network as a whole.
To understand deep networks and how they should be better designed, we must start with the objective of representation learning. In previous chapters, we have argued that the objective is to identify the intrinsically low-dimensional data distribution and then transform it to a compact and structured (say piecewise linear) representation. As we have seen in the previous chapter, the general approach to identifying a low-dimensional data distribution is through a compression process that progressively minimizes the entropy or coding rate of the distribution. However, up to this point, we have been using empirically designed deep networks to model or approximate the operations that aim to optimize these objectives, such as the score function for denoising (in Equation (1.3.21)) or the transformation that maximizes the rate reduction (in Section 4.2.4).
As we have argued in the previous chapter, Section 4.2 in particular, one can measure the goodness of the resulting representation by the information of the representation gained from a “lazy” representation which models all data as one big Gaussian.1 In particular, if we use a mixture of Gaussians (subspaces)2 as prototypical distributions to approximate the non-linear distribution of interest, then we can efficiently measure the coding rate of such a representation using the (sum of) rate distortion functions of the associated Gaussians. Then the amount of information gained or (relative) entropy reduced with such a modeling can be measured by the difference between the coding rate for the lazy representation and that for the more refined representation. Then, the objective of representation learning is to maximize this information gain, also known as the rate reduction objective.
As we will see in this chapter, once the objective of representation learning is clear, the role of a deep neural network is precisely to help optimize the objective iteratively. Each layer of a deep neural network can be naturally derived as an iterative optimization step to incrementally maximize the information gain, including the popular architectures of ResNet, CNN, and Transformer, and other more advanced variants. In particular, this chapter aims to answer the following questions about deep networks:
Now, if we agree that maximizing the rate reduction or information gain leads to the desired representation as discussed in Section 4.2, the remaining question is how to construct and learn a (nonlinear) mapping from the data \(\X \) to the optimal representation \(\Z ^*\). This involves designing a network architecture and learning algorithm that can effectively capture the underlying structures in the data and faithfully realize the optimal representation.
In the previous chapter, we presented the rate reduction objective (4.2.15) as a principled objective for learning linear discriminative representations of the data. We have, however, not specified the architecture of the feature mapping \(\z = f(\x , \bm \theta )\) for extracting such representations from input data \(\x \). A straightforward choice is to use a conventional deep network, such as ResNet, for implementing \(f(\x , \bm \theta )\). As we have seen in Section 4.3.1, such a choice often leads to decent performance empirically. Nonetheless, there remain several unanswered problems with adopting an arbitrary deep network. Although the learned feature representation is now more interpretable, the network itself is still not. It is unclear why any chosen “black-box” network is able to optimize the desired MCR\(^2\) objective at all. The good empirical results (say with a ResNet) do not necessarily justify the particular choice in architectures and operators of the network: Why is a deep layered model even necessary; what do additional layers try to improve or simplify; how wide and deep is adequate; or is there any rigorous justification for the convolutions (in a popular multi-channel form) and nonlinear operators (e.g. ReLU or softmax) used?
In this chapter, we show that using gradient ascent to maximize the rate reduction \(\Delta R_{\epsilon }(\Z \mid \bm \Pi )\) as defined in (4.2.15) naturally leads to a “white-box” deep network that realizes the desired mapping. All network layers, linear/nonlinear operators, and parameters are explicitly constructed in a purely forward propagation fashion. Moreover, such network architectures resemble existing empirically-designed deep networks, providing principled justifications for their design.
Gradient ascent for coding rate reduction. From the previous chapter, we see that to seek a linear discriminative representation (LDR), mathematically, we are essentially seeking a continuous mapping \(f(\cdot ): \x \mapsto \z \) from the data \(\X = [\x _1, \ldots , \x _N] \in \Re ^{D \times N}\) (or initial features extracted from the data3) to an optimal representation \(\Z = [\z _1, \ldots , \z _N] \in \Re ^{d \times N}\) that maximizes the following coding rate reduction objective (also see (4.2.17)):
where \(\epsilon > 0\) is a prescribed quantization error and for simplicity we denote4
The question really boils down to whether there is a constructive way of finding such a continuous mapping \(f(\cdot ,\bm \theta )\) from \(\bm x\) to \(\bm z\)? To this end, let us consider incrementally maximizing the objective \(\Delta R_{\epsilon }\) as a function of \(\Z \subseteq \mathbb {S}^{d-1}\). Although there might be many optimization schemes to choose from, for simplicity we first consider the arguably simplest projected gradient ascent (PGA) scheme:5
for some step size \(\eta >0\) and the iterate starts with the given data \(\bm Z^{0} = \bm X\).6 This scheme can be interpreted as how one should incrementally adjust locations of the current features \(\Z ^\ell \), initialized as the input data \(\bm X\), in order for the resulting \(\Z ^{\ell +1}\) to improve the rate reduction \(\Delta R_{\epsilon }\), as illustrated in Figure 5.1.
Simple calculation shows that the gradient \({\partial \Delta R_{\epsilon }}/{\partial \bm Z}\) entails evaluating the following derivatives of the two terms in \(\Delta R_{\epsilon }\):
Notice that in the above, the matrix \(\bm E^{\ell }\) only depends on \(\Z ^{\ell }\) and it aims to expand all the features to increase the overall coding rate; the matrix \(\bm C^{\ell }_{k}\) depends on features from the \(k\)-class and aims to compress them to reduce the coding rate of each class. Then the complete gradient \(\frac {\partial \Delta R_{\epsilon }}{\partial \bm Z}(\Z ^\ell ) \in \Re ^{d\times N}\) is of the form:
Remark 5.1 (Interpretation of \(\bm E^\ell \) and \(\bm C_j^\ell \) as linear operators). For any \(\bm z^\ell \in \mathbb {R}^d\),

Essentially, the linear operations \(\bm E^\ell \) and \(\bm C_k^\ell \) in gradient ascent for rate reduction are determined by training data conducting “auto-regressions”. The recent renewed understanding about ridge regression in an over-parameterized setting [WX20; YYY+20] indicates that using seemingly redundantly sampled data (from each subspace) as regressors do not lead to overfitting.
Gradient-guided feature map increment. Notice that in the above, the gradient ascent considers all the features \(\Z ^{\ell } = [\z ^{\ell }_{1}, \dots , \z ^{\ell }_{N}]\) as free variables. The increment \(\Z ^{\ell +1} - \Z ^{\ell } = \eta \frac {\partial \Delta R_{\epsilon }}{\partial \bm Z}(\Z ^\ell )\) does not yet give a transformation on the entire feature domain \(\z ^\ell \in \Re ^d\). According to equation (5.1.6), the gradient cannot be evaluated at a point whose membership is not known, as illustrated in Figure 5.1. Hence, in order to find the optimal \(f(\x ,\bm \theta )\) explicitly, we may consider constructing a small increment transform \(g(\cdot , \theta ^{\ell })\) on the \(\ell \)-th layer feature \(\z ^\ell \) to emulate the above (projected) gradient scheme:
such that \(\big [g(\z _1^{\ell }, \bm \theta ^{\ell }), \ldots , g(\z _N^{\ell }, \bm \theta ^{\ell }) \big ] \approx \frac {\partial \Delta R_{\epsilon }}{\partial \bm Z}(\Z ^\ell ).\) That is, we need to approximate the gradient flow \(\frac {\partial \Delta R_{\epsilon }}{\partial \bm Z}\) that locally deforms all (training) features \(\{\z _i^\ell \}_{i=1}^N\) with a continuous mapping \(g(\z ,\bm \theta )\) defined on the entire feature space \(\z ^\ell \in \Re ^d\). Notice that one may interpret the increment (5.1.9) as a discretized version of a continuous differential equation:
Hence the (deep) network so constructed can be interpreted as a certain neural ODE [CRB+18]. Nevertheless, unlike neural ODE where the flow \(g\) is chosen to be some generic structures, here our \(g(\z , \bm \theta )\) is to emulate the gradient flow of the rate reduction on the feature set (as shown in Figure 5.1):
and its structure is entirely derived and fully determined from this objective, without any other priors or heuristics.
By inspecting the structure of the gradient (5.1.6), it suggests that a natural candidate for the increment transform \(g(\z ^\ell , \bm \theta ^\ell )\) is of the form:
where \(\pi _k(\z ^\ell ) \in [0,1]\) indicates the probability of \(\z ^{\ell }\) belonging to the \(k\)-th class. The increment map parameters \(\bm \theta ^\ell \) depend on: First, a set of linear maps represented by \(\bm E^{\ell }\) and \(\{ \bm C^{\ell }_{k}\}_{k=1}^{K}\) that depend only on statistics of features of the training \(\Z ^\ell \); Second, the membership \(\{ \pi _k(\z ^\ell )\}_{k=1}^K\) of any feature \(\z ^\ell \). Notice that on the training samples \(\Z ^\ell \), for which the memberships \(\bm \Pi _k\) are known, the so defined \(g(\z ^\ell , \bm \theta )\) gives exactly the values for the gradient \(\frac {\partial \Delta R_{\epsilon }}{\partial \bm Z}(\Z ^\ell )\).
Since we only have the membership for the training samples, the function \(g(\cdot )\) defined in (5.1.11) can only be evaluated on the training. To extrapolate \(g(\cdot )\) to the entire feature space, we need to estimate \(\pi _k(\z ^\ell )\) in its second term. In conventional deep learning, this map is typically modeled as a deep network and learned from the training data, say via back propagation. Nevertheless, our goal here is not to learn a precise classifier \(\pi _{k}(\z ^\ell )\) already. Instead, we only need a good enough estimate of the class information in order for \(g(\cdot )\) to approximate the gradient \(\frac {\partial \Delta R_{\epsilon }}{\partial \bm Z}\) well.
From the geometric interpretation of the linear maps \(\bm E^\ell \) and \(\bm C_k^\ell \) given by Remark 5.1, the term \(\bm p_{k}^{\ell } \doteq \bm C^{\ell }_k \z ^{\ell }\) can be viewed as (approximately) the projection of \(\z ^{\ell }\) onto the orthogonal complement of each class \(j\). Therefore, \(\|\bm p_{j}^{\ell }\|_2\) is small if \(\z ^\ell \) is in class \(j\) and large otherwise. This motivates us to estimate its membership based on the following softmax function:
Hence, the second term of (5.1.11) can be approximated by this estimated membership:
which is denoted as a nonlinear operator \(\bm \sigma (\cdot )\) on outputs of the feature \(\z ^\ell \) through \(K\) groups of filters: \([\bm {C}^{\ell }_{1}, \dots , \bm {C}^{\ell }_{K}]\). Notice that the nonlinearality arises due to a “soft” assignment of class membership based on the feature responses from those filters.
Overall, combining (5.1.9), (5.1.11), and (5.1.14), the increment feature transform from \(\z ^{\ell }\) to \(\z ^{\ell +1}\) now becomes
with the nonlinear function \(\bm \sigma (\cdot )\) defined above and \(\bm \theta ^\ell \) collecting all the layer-wise parameters. That is \(\bm \theta ^\ell =\left \{\bm E^\ell , \bm {C}^{\ell }_{1}, \dots , \bm {C}^{\ell }_{K}, \gamma _{k}, \lambda \right \}\). Note features at each layer are always “normalized” by projecting onto the unit sphere \(\mathbb S^{d-1}\), denoted as \(\mathcal P_{\mathbb S^{d-1}}\), i.e., dividing each feature by its norm.7 The form of increment in (5.1.15) can be illustrated by a diagram in Figure 5.3(a).
Deep network for optimizing rate reduction. Notice that the increment is constructed to emulate the gradient ascent for the rate reduction \(\Delta R_\epsilon \). Hence by transforming the features iteratively via the above process, we expect the rate reduction to increase, as we will see in the experimental section. This iterative process, once converged, say after \(L\) iterations, gives the desired feature map \(f(\x , \bm \theta )\) on the input \(\x = \z ^0\), precisely in the form of a deep network, in which each layer has the structure shown in Figure 5.3 left:
As this deep network is derived from maximizing the rate reduction, we call it the ReduNet. By comparing the architecture of ReduNet with those of popular empirically designed networks, ResNet and ResNeXt shown in Figure 5.3, the similarity is somewhat uncanny. Conceptually, ReduNet could also be used to justify the popular mixture of experts (MoE) architecture [SMM+17] as each parallel channel, \(\bm {C}^{\ell }_k\), can be viewed as an “expert” trained for each class of objects.
We summarize the training and evaluation of ReduNet in Algorithm 5.1 and Algorithm 5.2, respectively. Notice that all parameters of the network are explicitly constructed layer by layer in a forward propagation fashion. The construction does not need any back propagation! The so-learned features can be directly used for classification, say via a nearest subspace classifier.
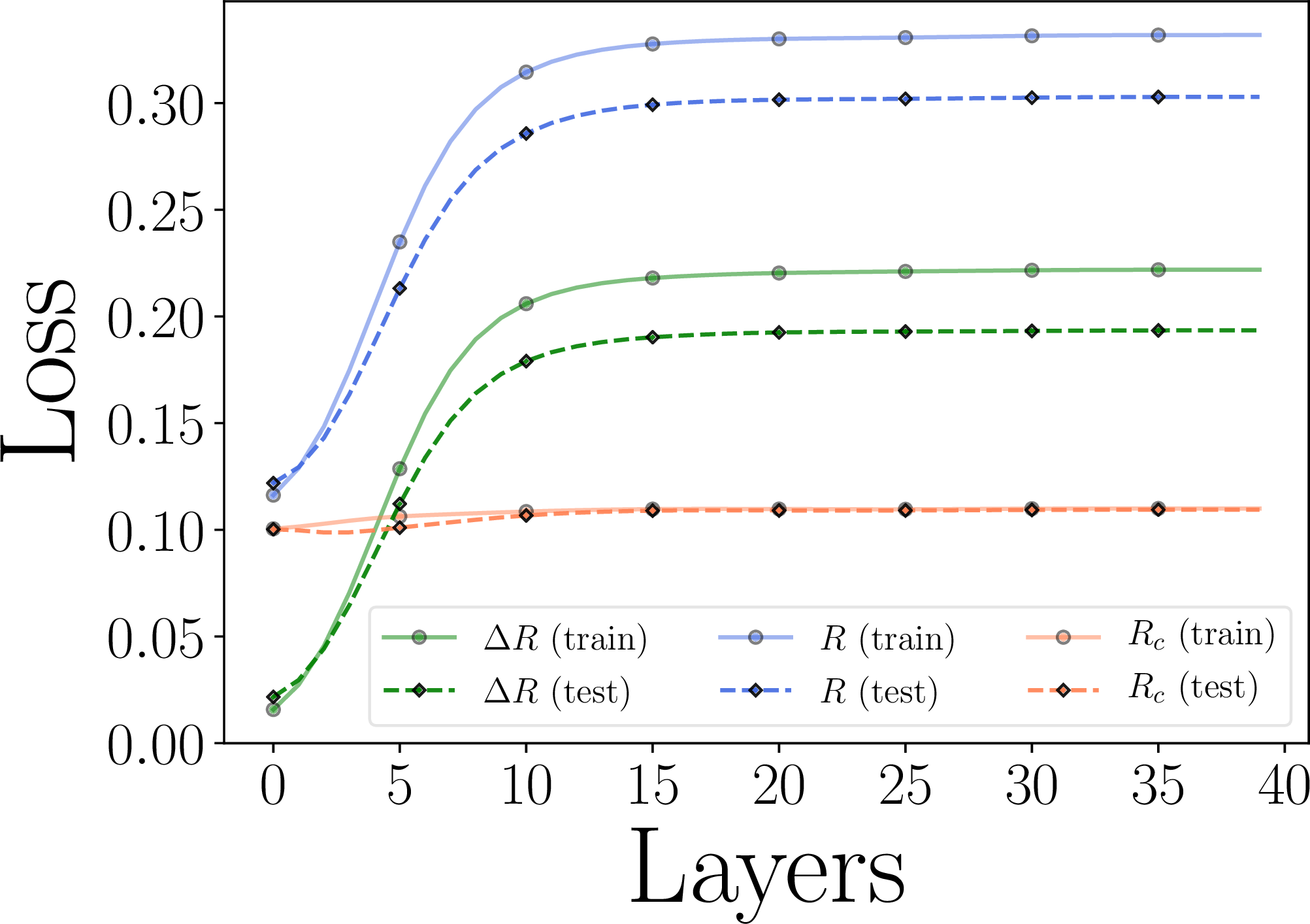
Example 5.1. To provide some intuition on how ReduNet transforms the features, we provide a simple example with mixed 3D Gaussians and visualize how the features are transformed in Figure 5.5. Consider a mixture of three Gaussian distributions in \(\R ^{3}\) that is projected onto \(\mathbb {S}^2\). We first generate data points for 3 classes: for \(k=1,2,3\), \(\bm {X}_{k}=[\bm {x}_{k,1}, \ldots , \bm {x}_{k,m}] \in \R ^{3\times m}\), \(\bm {x}_{k,i} \sim \mathcal {N}(\bm {\mu }_{k}, \sigma _{k}^{2} \I )\), and \({\pi }(\x _{k,i}) = k\). We set \(m=500, \sigma _{1}=\sigma _{2}=\sigma _{3}=0.1\), and \(\bm {\mu }_{1}, \bm {\mu }_{2}, \bm {\mu }_{3} \in \mathbb {S}^2\). Then we project all the data points onto \(\mathbb {S}^{2}\), i.e., \(\bm {x}_{k,i}/\|\bm {x}_{k,i}\|_{2}\). To construct the network (computing \(\bm {E}^{\ell }, \bm {C}^{\ell }_{k}\) for the \(\ell \)-th layer), we set the number of iterations/layers \(L=2,000\), step size \(\eta =0.5\), and precision \(\epsilon =0.1\). We do this only to demonstrate that our framework leads to stable deep networks even with thousands of layers. In practice, thousands of layers may not be necessary and one can stop whenever adding new layers gives diminishing returns. For this example, a couple of hundred layers is sufficient. Hence, the clear optimization objective gives a natural criterion for the depth of the network needed.
As shown in Figure 5.5, we can observe that after the mapping \(f(\cdot , \theta )\), samples from the same class are highly compressed and converge to a single cluster and the angle between two different clusters is approximately \(\pi /2\), which is well aligned with the optimal solution \(\Z ^{\star }\) of the MCR\(^2\) loss in \(\mathbb {S}^2\). MCR\(^2\) loss of features on different layers can be found in Figure 5.5(c). Empirically, we find that the constructed ReduNet is able to maximize MCR\(^2\) loss and converges stably and samples from the same class converge to one cluster and points in different clusters are orthogonal to each other.8 Moreover, when sampling new data points from the same distributions, we find that new samples from the same class consistently converge to the same cluster center as the training samples.
In the previous section, we derived the layer-wise architecture of a deep network, the ReduNet, using unrolled optimization for the rate reduction objective. Specifically, the compression term \(R^c_\epsilon (\Z \mid \bm \Pi )\) in (5.1.1) is designed to compress representations from the same class. However, this formulation does not account for possible domain transformation or deformation of the input data. For instance, shifting an object slightly to the right does not change the semantic label of an image. In this section, we will demonstrate how convolutional layers can be derived by maximizing a rate reduction objective that is invariant to certain domain deformations, such as image rotations and translations.
For many clustering or classification tasks (such as object detection in images), we consider two samples as equivalent if they differ by certain classes of domain deformations or augmentations \(\cT = \{\tau \}\). Hence, we are only interested in low-dimensional structures that are invariant to such deformations (i.e., \(\x \in \mathcal {M}\) iff \(\tau (\x ) \in \mathcal {M}\) for all \(\tau \in \cT \) ), which are known to have sophisticated geometric and topological structures and can be difficult to learn precisely in practice, even with rigorously designed CNNs [CW16a]. In this framework, this can be formulated in a very natural way: all equivariant instances are to be embedded into the same subspace, so that the subspace itself is invariant to the transformations under consideration.
In many applications, such as serial data or imagery data, the semantic meaning (labels) of the data are invariant to certain transformations \(\mathfrak {g} \in \mathbb {G}\) (for some group \(\mathbb {G}\)) [CW16c; ZKR+17]. For example, the meaning of an audio signal is invariant to shift in time; and the identity of an object in an image is invariant to translation in the image plane. Hence, we prefer the feature mapping \(f(\x ,\bm \theta )\) is rigorously invariant to such transformations:
where “\(\sim \)” indicates two features belonging to the same equivalent class. Although to ensure invariance or equivarience, convolutional operators have been common practice in deep networks [CW16c], it remains challenging in practice to train an (empirically designed) convolution network from scratch that can guarantee invariance even to simple transformations such as translation and rotation [AW18; ETT+17]. An alternative approach is to carefully design convolution filters of each layer so as to ensure translational invariance for a wide range of signals, say using wavelets as in ScatteringNet [BM13] and followup works [WB18]. However, in order to ensure invariance to generic signals, the number of convolutions needed usually grows exponentially with network depth. That is the reason why this type of network cannot be constructed so deep, usually only several layers.
Now, we show that the MCR\(^2\) principle is compatible with invariance in a natural and precise way: we only need to assign all transformed versions \(\{\x \circ \mathfrak {g} \mid \mathfrak {g} \in \mathbb G\}\) into the same class as the data \(\x \) and map their features \(\z \) all to the same subspace \(\mathcal S\). Hence, all group equivariant information is encoded only inside the subspace, and any classifier defined on the resulting set of subspaces will be automatically invariant to such group transformations. See Figure 5.6 for an illustration of the examples of 1D rotation and 2D translation. Next, we will rigorously show that when the group \(\mathbb G\) is circular 1D shifting, the resulting deep network naturally becomes a multi-channel convolution network. Because the so-constructed network only needs to ensure invariance for the given data \(\X \) or their features \(\Z \), the number of convolutions needed actually remains constant through a very deep network, as opposed to the ScatteringNet.
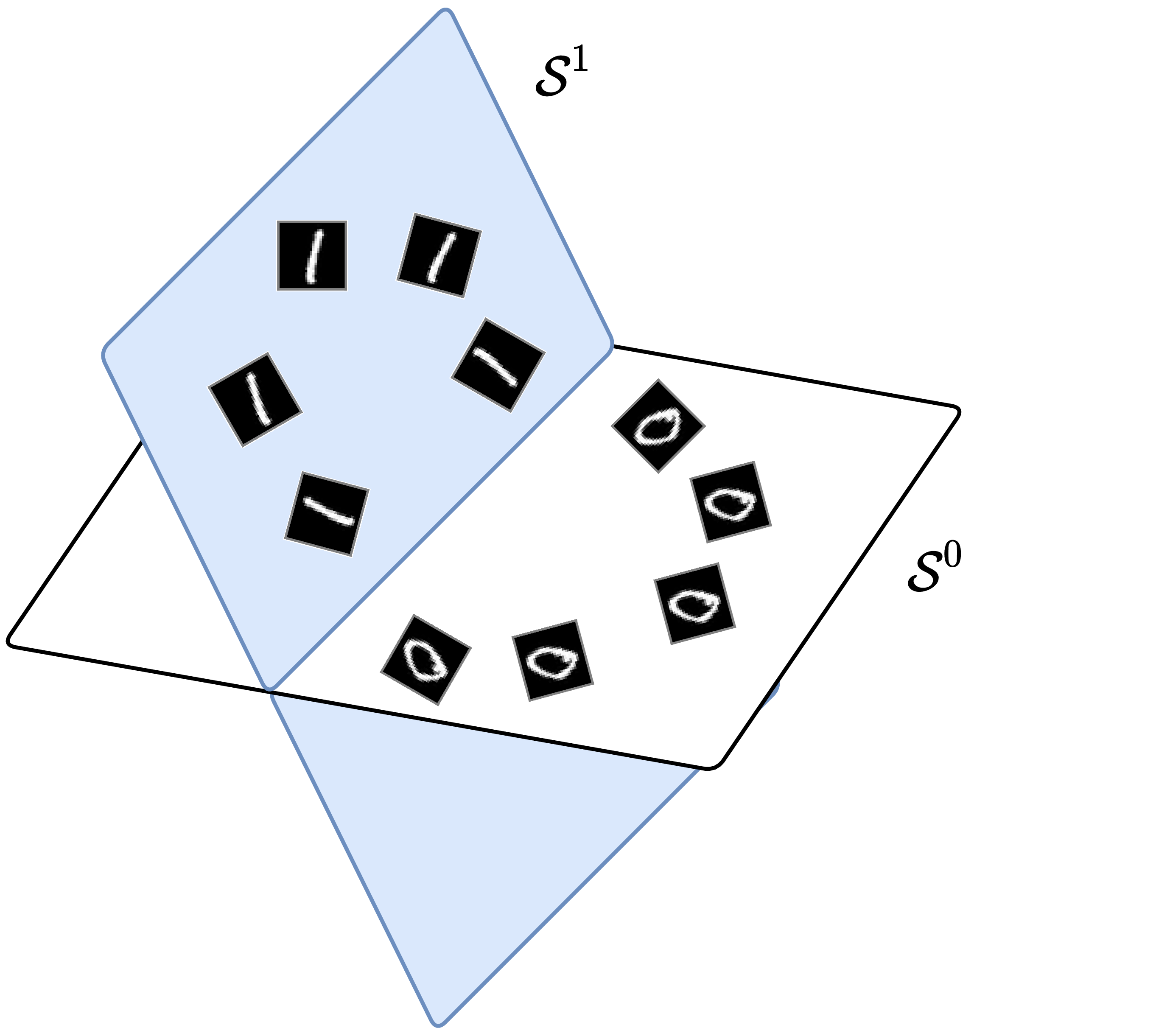
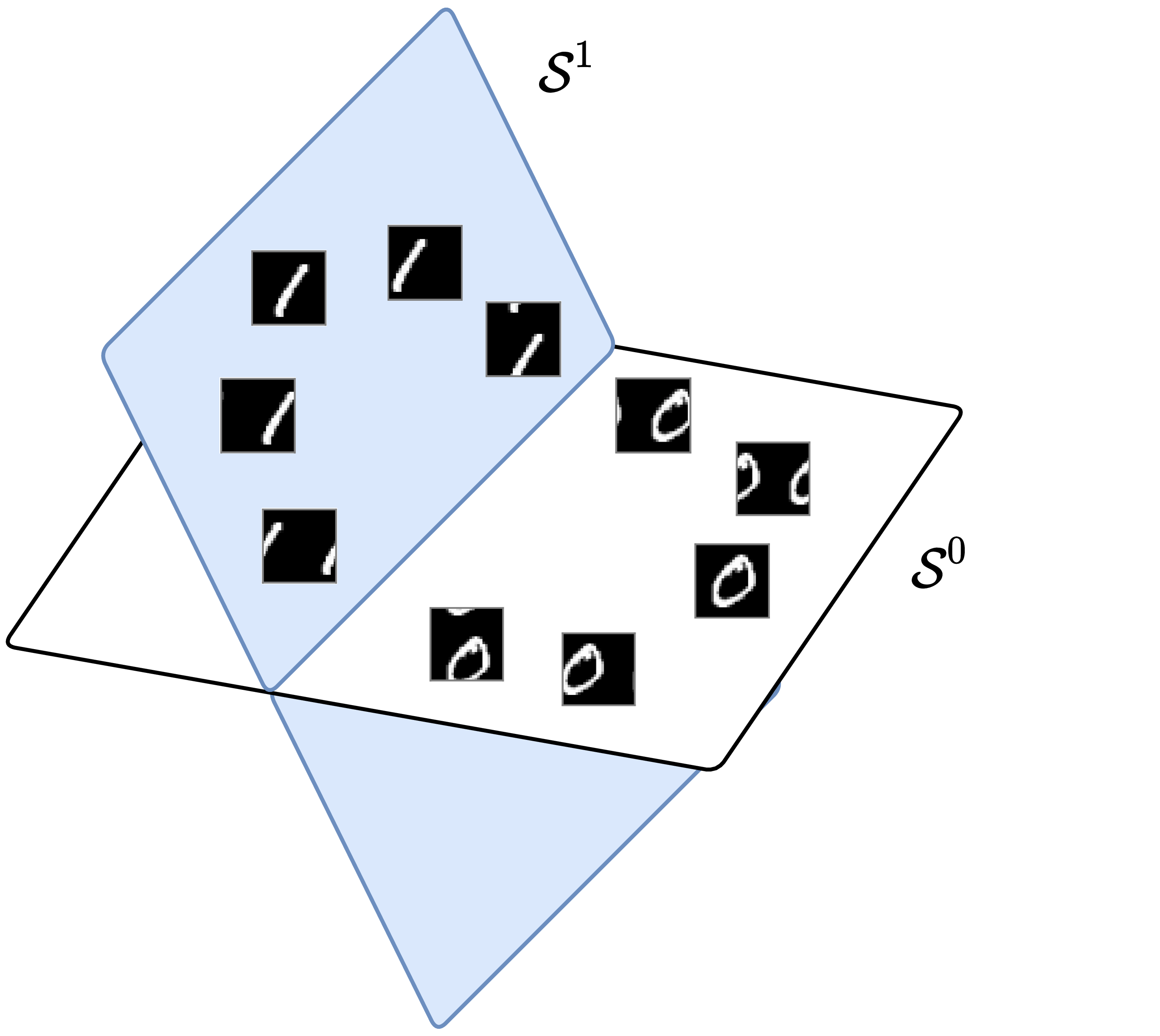
1D serial data and shift invariance To classify one-dimensional data \(\bm x = [x(0), x(1), \ldots , x(D-1)] \in \Re ^D\) invariant under shifting, we take \(\mathbb {G}\) to be the group of all circular shifts. Each observation \(\bm x_i\) generates a family \(\{ \x _i \circ \mathfrak {g} \, | \, \mathfrak {g} \in \mathbb G \}\) of shifted copies, which are the columns of the circulant matrix \(\circm (\bm x_i) \in \Re ^{D \times D}\) given by
We refer the reader to [KS12] for properties of circulant matrices. For simplicity, let \(\bm Z^1 \doteq [ \z _{1}^1, \dots , \z _{N}^1 ] = \X \in \Re ^{d \times N}\).9 Then what happens if we construct the ReduNet from their circulant families \(\circm (\bm Z^1) = \left [ \circm (\z _{1}^1), \dots , \circm (\z _{N}^1) \right ] \in \Re ^{d \times (dN)}\)? That is, we want to compress and map all these into the same subspace by the ReduNet.
Notice that now the data covariance matrix:
associated with this family of samples is automatically a (symmetric) circulant matrix. Moreover, because the circulant property is preserved under sums, inverses, and products, the matrices \(\bm E^1\) and \(\bm C^1_k\) are also automatically circulant matrices, whose application to a feature vector \(\bm z \in \Re ^d\) can be implemented using circular convolution “\(\circledast \)”. Specifically, we have the following proposition.
Proposition 5.1 (Convolution structures of \(\bm E^1\) and \(\bm C^1_k\)). The matrix
Not only do the first-layer parameters \(\bm E^1\) and \(\bm {C}^1_k\) of the ReduNet become circulant convolutions but also the next-layer features remain circulant matrices. That is, the incremental feature transform in (5.1.15) applied to all shifted versions of a \(\z ^1 \in \Re ^d\), given by
is a circulant matrix. This implies that there is no need to construct circulant families from the second layer features as we did for the first layer. By denoting
the features at the next level can be written as
Continuing inductively, we see that all matrices \(\bm E^\ell \) and \(\bm C^\ell _k\) based on such \(\circm (\bm Z^\ell )\) are circulant, and so are all features. By virtue of the properties of the data, ReduNet has taken the form of a convolutional network, with no need to explicitly choose this structure!
A fundamental trade-off between invariance and sparsity. There is one problem though: In general, the set of all circular permutations of a vector \(\z \) gives a full-rank matrix. That is, the \(d\) “augmented” features associated with each sample (hence each class) typically already span the entire space \(\Re ^d\). For instance, all shifted versions of a delta function \(\delta (d)\) can generate any other signal as their (dense) weighted superposition. The MCR\(^2\) objective (4.2.15) will not be able to distinguish classes as different subspaces.
One natural remedy is to improve the separability of the data by “lifting” the original signal to a higher dimensional space, e.g., by taking their responses to multiple, filters \(\bm k_1, \ldots , \bm k_C \in \Re ^d\):
The filters can be pre-designed invariance-promoting filters,10 or adaptively learned from the data,11 or randomly selected as we do in our experiments. This operation lifts each original signal \(\x \in \Re ^d\) to a \(C\)-channel feature, denoted as \(\bar {\z } \doteq [\z [1], \ldots , \z [C]]^\top \in \Re ^{C\times d}\). Then, we may construct the ReduNet on vector representations of \(\bar {\z }\), denoted as \(\vec (\bar \z ) \doteq [\z [1]^\top , \ldots , \z [C]^\top ] \in \Re ^{dC}\). The associated circulant version \( \circm (\bar {\z })\) and its data covariance matrix, denoted as \(\bar {\bm \Sigma }(\bar \z )\), for all its shifted versions are given as:
where \(\circm (\z [c]) \in \Re ^{d\times d}\) with \(c \in [C]\) is the circulant version of the \(c\)-th channel of the feature \(\bar \z \). Then the columns of \(\circm (\bar \z )\) will only span at most a \(d\)-dimensional proper subspace in \(\Re ^{dC}\). However, this simple lifting operation (if linear) is not sufficient to render the classes separable yet—features associated with other classes will span the same \(d\)-dimensional subspace. This reflects a fundamental conflict between invariance and linear (subspace) modeling: one cannot hope for arbitrarily shifted and superposed signals to belong to the same class.

One way of resolving this conflict is to leverage additional structure within each class, in the form of sparsity: signals within each class are not generated as an arbitrary linear superposition of some base atoms (or motifs), but only sparse combinations of them and their shifted versions, as shown in Figure 5.7. More precisely, let \(\bm D_k = [\bm d_{k,1}, \ldots , \bm d_{k,c}]\) denote a matrix with a collection of atoms associated for class \(k\), also known as a dictionary, then each signal \(\x \) in this class is sparsely generated as:
for some sparse vector \(\z \). Signals in different classes are then generated by different dictionaries whose atoms (or motifs) are incoherent from one another. Due to incoherence, signals in one class are unlikely to be sparsely represented by atoms in any other class. Hence all signals can be represented as
where \(\bar \z \) is sparse.12 There is a vast literature on how to learn the most compact and optimal sparsifying dictionaries from sample data, e.g. [LB19; QLZ19] and subsequently solve the inverse problem and compute the associated sparse code \(\z \) or \(\bar \z \). Recent studies of [QLZ20; QZL+20a] even show that under broad conditions the convolution dictionary learning problem can be solved effectively and efficiently.
Nevertheless, for tasks such as classification, we are not necessarily interested in the precise optimal dictionary nor the precise sparse code for each individual signal. We are mainly interested if collectively the set of sparse codes for each class are adequately separable from those of other classes. Under the assumption of the sparse generative model, if the convolution kernels \(\{\bm k_c\}_{c=1}^C\) match well with the “transpose” or “inverse” of the above sparsifying dictionaries \(\bm D = [\bm D_1, \ldots , \bm D_K]\), also known as the analysis filters [NDE+13; RE14], signals in one class will only have high responses to a small subset of those filters and low responses to others (due to the incoherence assumption). Nevertheless, in practice, often a sufficiently large number of, say \(C\), random filters \(\{\bm k_c\}_{c=1}^C\) suffices to ensure that the extracted \(C\)-channel features
for different classes have different response patterns to different filters hence make different classes separable [CJG+15].
Therefore, in our framework, to a large extent the number of channels (or the width of the network) truly plays the role as the statistical resource whereas the number of layers (the depth of the network) plays the role as the computational resource. The theory of compressive sensing precisely characterizes how many measurements are needed in order to preserve the intrinsic low-dimensional structures (including separability) of the data [WM22].

The multi-channel responses \(\bar \z \) should be sparse. So to approximate the sparse code \(\bar \z \), we may take an entry-wise sparsity-promoting nonlinear thresholding, say \(\bm \tau (\cdot )\), on the above filter outputs by setting low (say absolute value below \(\epsilon \)) or negative responses to be zero:
Figure 5.8 illustrates the basic ideas. One may refer to [RE14] for a more systematical study on the design of the sparsifying thresholding operator. Nevertheless, here we are not so interested in obtaining the best sparse codes as long as the codes are sufficiently separable. Hence the nonlinear operator \(\bm \tau \) can be simply chosen to be a soft thresholding or a ReLU. These presumably sparse features \(\bar \z \) can be assumed to lie on a lower-dimensional (nonlinear) submanifold of \(\mathbb {R}^{dC}\), which can be linearized and separated from the other classes by subsequent ReduNet layers, as illustrated later in Figure 5.9.
The ReduNet constructed from circulant version of these multi-channel features \(\bar \Z \doteq [\bar \z _1, \ldots , \bar \z _N] \in \Re ^{C \times d \times N}\), i.e., \(\circm (\bar \Z ) \doteq [ \circm (\bar \z _1), \dots , \circm (\bar \z _N)] \in \Re ^{dC \times dN}\), retains the good invariance properties described above: the linear operators, now denoted as \(\bar {\bm E}\) and \(\bar {\bm C}_k\), remain block circulant, and represent multi-channel 1D circular convolutions. Specifically, we have the following result.
Proposition 5.2 (Multi-channel convolution structures of \(\bar {\bm E}\) and \(\bar {\bm C}_k\)). The matrix
From Equation (5.1.30), shift invariant ReduNet is a deep convolutional network for multi-channel 1D signals by construction. Notice that even if the initial lifting kernels are separated (5.1.32), the matrix inverse in (5.1.33) for computing \(\bar {\bm E}\) (similarly for \(\bar {\bm C_k}\)) introduces “cross talk” among all \(C\) channels. Hence, these multi-channel convolutions in general are not depth-wise separable, unlike the Xception nets [Cho17] that were once suggested to simplify multi-channel convolutional neural networks.13
Remark 5.2 (Reducing Computational Complexity in the Frequency Domain). The calculation of \(\bar {\bm E}\) in (5.1.33) requires inverting a matrix of size \(dC \times dC\), which in general has complexity \(O(d^3C^3)\). Nevertheless, by using the fact that a circulant matrix can be diagonalized by the Discrete Fourier Transform (DFT) matrix, the complexity can be significantly reduced. As shown in [CYY+22], to compute \(\bar {\bm E}\) and \(\bar {\bm C}_k \in \Re ^{dC \times dC}\), we only need to compute in the frequency domain the inverse of \(C\times C\) blocks for \(d\) times hence the overall complexity becomes \(O(dC^3)\).
Overall network architecture and comparison. Following the above derivation, we see that in order to find a linear discriminative representation (LDR) for multiple classes of signals/images that is invariant to translation, sparse coding, a multi-layer architecture with multi-channel convolutions, different nonlinear activation, and spectrum computing all become necessary components for achieving the objective effectively and efficiently. Figure 5.9 illustrates the overall process of learning such a representation via invariant rate reduction on the input sparse codes.
Example 5.2 (Invariant Classification of Digits). We next provide an empirical performance of the ReduNet on learning rotation invariant features on the real 10-class MNIST dataset. We impose a polar grid on the image \(\bm {x}\in \mathbb {R}^{H\times W}\), with its geometric center being the center of the 2D polar grid (as illustrated in Figure 5.10). For each radius \(r_i\), \(i \in [C]\), we can sample \(\Gamma \) pixels with respect to each angle \(\gamma _l =l\cdot ({2\pi }/\Gamma )\) with \(l \in [\Gamma ]\). Then given a sample image \(\bm {x}\) from the dataset, we represent the image in the (sampled) polar coordinate as a multi-channel signal \(\bm {x}_p \in \R ^{\Gamma \times C}\). The goal here is to learn a rotation invariant representation, i.e., we expect to learn \(f(\cdot , \theta )\) such that \(\{f(\bm {x}_p \circ \mathfrak {g}, \theta )\}_{\mathfrak {g} \in \mathbb {G}}\) lie in the same subspace, where \(\mathfrak {g}\) is the cyclic-shift in polar angle. We use \(N=100\) training samples (\(10\) from each class) and set \(\Gamma =200\), \(C=15\) for polar sampling. By performing the above sampling in polar coordinate, we can obtain the data matrix \(\bm {X}_p \in \mathbb {R}^{(\Gamma \cdot C) \times N}\). For the ReduNet, we set the number of layers/iterations \(L=40\), precision \(\epsilon =0.1\), step size \(\eta =0.5\). Before the first layer, we perform lifting of the input by 1D circulant-convolution with 20 random Gaussian kernels of size 5.
To evaluate the learned representation, each training sample is augmented by 20 of its rotated version, each shifted with stride=10. We compute the cosine similarities among the \(m \times 20\) augmented training inputs \(\bm {X}_{\text {rotation}}\) and the results are shown in Figure 5.11 (a). We compare the cosine similarities among the learned features of all the augmented versions, i.e., \(\bar {\bm {Z}}_{\text {rotation}}\) and summarize the results in Figure 5.11 (b). As we see, the so-constructed rotation-invariant ReduNet is able to map the training data (as well as all its rotated versions) from the 10 different classes into 10 nearly orthogonal subspaces. That is, the learned subspaces are truly invariant to shift transformation in polar angle. Next, we randomly draw another \(100\) test samples followed by the same augmentation procedure. In Figure 5.11 (c), we visualize the MCR\(^{2}\) loss on the \(\ell \)-th layer representation of the ReduNet on the training and test dataset. From these results, we can find that the constructed ReduNet is indeed able to maximize the MCR\(^{2}\) loss as well as generalize to the test data.
As we have seen in the previous section, we use the problem of classification to provide a rigorous interpretation for main architectural characteristics of popular deep networks such as the ResNet and the CNN: each layer of such networks can be viewed as to imitate a gradient step which increases the rate reduction (or information gain) objective. This perspective also leads to a somewhat surprising fact: the the parameters and operators of the layers of such a deep network, the ReduNet, can be computed in a purely forward fashion.
Despite the theoretical and conceptual importance of the ReduNet, several factors limit it from being very practical. First, as we have discussed in the above, the computational cost of computing the matrix operators in each layer in a forward fashion can be very high. Second, the so-computed operators may not be so effective in optimizing the objective and it might take thousands of iterations (hence layers). As we have seen in Section 2.3.3 for LISTA, these two issues can be addressed by allowing to optimize those operators and make them learnable via back-propagation.14
The supervised classification setting in which the ReduNet was derived is also somewhat limiting. In practice, an image might not belong to a single class as it may contain multiple objects. Hence it would be more general to assume that different regions of the image belong to different low-dimensional models (say a Gaussian or a subspace). As we will see, such a generalization would lead to a both simple and general architecture which unifies the rate reduction and the denoising operations that we have seen in the previous chapter. Moreover, the so-obtained architecture resembles the popular Transformer architecture.
For the past several years, as the amount and quality of data available for training deep networks has increased dramatically, the field has moved from considering inputs as “atoms” to inputs as “sequences of tokens”, where each token is a part of the overall input. This shift in perspective has both philosophical and pragmatic improvements: philosophically, it allows us to measure and model each part of the input and their interactions; pragmatically, it allows us to use similar deep networks, sequence-to-sequence models such as the ubiquitous Transformers, to learn every kind of data distribution. Now, it falls to us to understand representation learning in the “token-centric” model of data as token sequences, and to cope with the aforementioned challenges (such as, in the context of the rate reduction framework, not having labels for each token).
Formally, let \(\X = \mat {\x _{1}, \dots , \x _{N}} \in \bR ^{D \times N}\) denote random variables representing our data source. In vision tasks, each \(\x _{i} \in \bR ^{D}\) is interpreted as a token, typically corresponding to an image patch. In language tasks, each \(\x _{i} \in \bR ^{D}\) is interpreted as an token embedding, i.e., a continuous vector representation of a discrete token such as a word or subword.15 The \(\x _{i}\)’s may have arbitrary correlation structures. We use \(\Z = \mat {\z _{1}, \dots , \z _{N}} \in \bR ^{d \times N}\) to denote the random variables that defines our representations, where \(\z _{i} \in \bR ^{d}\) is the representation of the corresponding token \(\x _i \in \bR ^{D}\).
Remark 5.3. In transformers, each input sample is typically converted into a sequence of tokens. A token is a basic unit of information derived from the raw input: in natural language processing, tokens are typically words or subwords; in computer vision, they correspond to image patches; and in other modalities, they may represent time steps, spatial locations, or other domain-specific units. A token embedding is a continuous vector representation of a token that serves as the input to a transformer. It maps each token to a point in a high-dimensional space, enabling the model to process symbolic inputs using numerical computation. A token representation is a vector that encodes the semantic or structural information of a token, typically produced by the intermediate or final layers of a transformer. These representations are designed to capture meaningful features of the input that are useful for downstream tasks such as classification, generation, or regression. Please refer to Section 8.2 for more details about this vocabulary and how it relates to implementations.
Objective for learning a structured and compact representation. Inspired by the previous discussion of rate reduction (Section 5.1), we propose that the objective of representation learning in this token-centric model for our data is to find a feature mapping \(f \colon \X \in \bR ^{D \times N} \to \Z \in \bR ^{d \times N}\) which transforms input tokens \(\{\bm x_i\}_{i=1}^N \subset \R ^D\) with a potentially nonlinear and multi-modal distribution to a (piecewise) linearized and compact token representations \(\{\bm z_i\}_{i=1}^N \subset \bR ^{d}\). While the joint distribution of tokens representations \(\{\z _{i}\}_{i = 1}^{N}\) may be sophisticated (and task-specific), we further contend that it is reasonable and practical to require that the target marginal distribution of individual token representations should be highly compressed and structured, amenable for compact coding. Particularly, we require the distribution to be a mixture of low-dimensional (say \(K\)) Gaussian distributions, such that the \(k\)-th Gaussian has mean \(\Zero \in \bR ^{d}\), covariance \(\vSigma _{k} \succeq \Zero \in \bR ^{d \times d}\), and support spanned by the orthonormal basis \(\vU _{k} \in \bR ^{d \times p}\). We denote \(\vU _{[K]} = \{\vU _k\}_{k=1}^K\) to be the set of bases of all Gaussians.
As usual, in order to learn good representations, we wish to maximize the information gain for the final token representations, or more specifically to maximize an appropriate notion of the rate reduction (see Section 4.2.3), i.e.,
Here, the first term \(R_{\epsilon }\) is an estimate of the lossy coding rate for the whole set of token representations. More specifically, if we view the token representations \(\{\bm z_i\}_{i=1}^N\) as i.i.d. samples from a single zero-mean Gaussian, their lossy coding rate subject to a quantization precision \(\epsilon > 0\) is given as
The second term \(R_{\epsilon }^c\) is an estimate of the lossy coding rate under the codebook \(\bm U_{[K]}\), which is given as
Remark 5.4. The expression (5.2.3) for the coding rate can be viewed as a generalization of the coding rate \(R_\epsilon ^{c}\) used in the original rate reduction objective (4.2.16). In particular, the original objective is defined with respect to a set of known membership labels \(\{\vPi _{k}\}\) specific to the particular data realization \(\vX \). In contrast, the current objective is defined with respect to subspaces \(\vU _{[K]}\), which are independent of any particular realization but are assumed to support the distribution of token representations. Suppose that a token representation \(\bm z_i\) belongs to a subspace \(\bm U_k\) and these subspaces are approximately orthogonal to each other, i.e., \(\bm U_k^\top \bm U_l \approx \bm 0\) for all \(k \neq l\). Then, one can verify that the projections \(\bm U_k\bm U_k^\top \bm z_i = \bm z_i\) and \(\bm U_l\bm U_l^\top \bm z_i \approx \bm 0\) for all \(l \neq k\). These orthogonal projections effectively serve as implicit membership labels, identifying the subspace to which each token representation belongs.
Remark 5.5. Notably, this set of desiderata for representation learning aligns well with two well-established empirical hypotheses about the structure of token representations in trained models which use the ubiquitous transformer neural network architecture: the “linear representation hypothesis” [JRR+24; PCV24] and the “superposition hypothesis” [EHO+22a; YCO+21]. The linear representation hypothesis posits that token representations in transformer models lie in low-dimensional linear subspaces that encode semantic features. Similarly, the superposition hypothesis suggests that these representations can be approximately expressed as a sparse linear combination of these feature vectors. As we will see in Figure 5.17 later in this Chapter, the subspace basis \(\bm U_k\) may be interpreted as a set of semantic features, where each feature corresponds to a specific aspect of the token’s meaning. Token representations are then approximately expressed as sparse linear combinations of these subspace bases, capturing the essential semantic components of the token while ignoring irrelevant dimensions.
Sparse rate reduction. Note that the rate reduction objective (5.2.1) is invariant to arbitrary joint rotations of the representations and subspaces. In particular, optimizing the rate reduction objective may not naturally lead to axis-aligned (i.e., sparse) representations. For instance, consider the three sets of learned representations in Figure 5.12. The coding rate reduction increases from (a) to (b), but because it is invariant under rotations, remains the same from (b) to (c). Therefore, we would like to transform the representations (and their supporting subspaces) so that the representations \(\vZ \) eventually become sparse16 with respect to the standard coordinates of the resulting representation space as in Figure 5.12(c). Computationally, we may combine the above two goals into a unified objective for optimization:
where \(\mathcal {F}\) denotes a general function class and the \(\ell _0\) norm \(\|\Z \|_0\) promotes the sparsity of the final token representations \(\Z = f(\X )\).
In practice, the \(\ell _0\) norm is often relaxed to the \(\ell _1\) norm to improve computational tractability and enable convex optimization techniques [WM22]. Motivated by this, we relax Problem (5.2.4) accordingly, leading to a formulation that remains faithful to the original sparsity objective while being more amenable to efficient algorithms as follow:
With a slight abuse of terminology, we often refer to this objective function also as the sparse rate reduction.
White-box network architecture via unrolled optimization. Although easy to state, each term in the above objective is computationally challenging to optimize [WM22]. Hence it is natural to adopt an approximation approach that realizes the global transformation \(f\) to optimize (5.2.4) through a concatenation of multiple, say \(L\), simple incremental and local operations \(f^\ell \) that push the representation distribution towards the desired parsimonious model distribution:
where \(f^{\mathrm {pre}}: \bR ^{D} \rightarrow \bR ^{d}\) is the pre-processing mapping that transforms each input token \(\x _{i} \in \bR ^{D}\) to the initial token representations \(\z _{i}^{1} \in \bR ^{d}\). Each incremental forward mapping \(\Z ^{\ell + 1} = f^\ell (\Z ^\ell )\), or a “layer”, transforms the token distribution to optimize the above sparse rate reduction objective (5.2.4), conditioned on the distribution of its input \(\Z ^\ell \).
Remark 5.6. In contrast to other unrolled optimization approaches such as the ReduNet (see Section 5.1), we explicitly model the distribution of \(\Z ^\ell \) at each layer, say as a mixture of linear subspaces or sparsely generated from a dictionary. The model parameters are learned from data (say via backward propagation with end-to-end training). This separation between forward “optimization” and backward “learning” clarifies the mathematical role of each layer as an operator that transforms the distribution of its input, whereas the input distribution is in turn modeled (and subsequently learned) by the parameters of the layer.
Now, we show how to derive these incremental and local operations through an unrolled optimization perspective to solve Problem (5.2.5). Once we decide on using an incremental approach to optimizing Problem (5.2.5), there are a variety of possible choices to achieve the optimization. Given a model for \(\Z ^\ell \), say a mixture of subspaces \(\vU _{[K]}\), we opt for a two-step alternating minimization method with a strong conceptual basis. First, we compress the tokens \(\vZ ^{\ell }\) via a gradient descent to minimize the coding rate term \(R^c_\epsilon (\vZ \mid \vU _{[K]}^\ell )\). Specifically, we take a gradient step on \(R^c_\epsilon \) with a learning rate \(\kappa \) as follows:
Next, we sparsify the compressed tokens, generating \(\vZ ^{\ell + 1}\) via a suitably-relaxed proximal gradient step to minimize the remaining term \(\lambda \norm {\vZ }_{1} - R_{\epsilon }(\vZ )\). As we will argue in detail later, we can find such a \(\bm Z^{\ell +1}\) by solving a sparse presentation problem with respect to an orthogonal complete dictionary \(\bm D^\ell \):
In the following, we provide technical details for each of the two steps above and derive efficient updates for their implementation.
Self-attention as gradient descent on coding rate of token representations. For the first step (5.2.7), the gradient of the coding rate \(\nabla _{\bm Z} R^c_\epsilon \) is costly to compute, as it involves \(K\) separate matrix inverses, one for each of the \(K\) subspaces with basis \(\vU _{k}^{\ell }\):
Now, we demonstrate that this gradient can be naturally approximated using a so-called multi-head subspace self-attention (MSSA) operator, which has a similar functional form to the multi-head self-attention operator [VSP+17b] with \(K\) heads (i.e., one for each subspace, coming from each matrix inverse). Here, we approximate the gradient (5.2.9) using the first-order Neumann series (see Exercise 5.2):17
In the above approximation, we compute the similarity between projected token representations \(\{\bm U_k^\top \bm z_i\}_{i = 1}^{n}\) through an auto-correlation among the projected features as \((\vU _{k}^\top \vZ )^\top (\vU _{k}^\top \vZ )\). Even if each token feature within \(\vZ \) is normalized, the norm of this matrix can grow arbitrarily18 as the sequence length increases, making our Neumann approximation increasingly poor (as the true gradient does not grow arbitrarily in size with sequence length). To fix this practical issue and generalize our formulation, we can instead use an arbitrary kernel to measure similarity. One particularly fitting kernel that aligns with our motivation of only auto-regressing against tokens which belong to the same subspace is the local (Nadaraya-Watson) kernel which involves membership estimation via softmax [CMP+21], namely computing (relative) similarity as \(\softmax ((\vU _{k}^\top \vZ )^\top (\vU _{k}^\top \vZ ))\). Now suppose that the subspaces expand “as much as possible”, that is, all subspaces’ bases \(\bm U_{[K]}\) together span the whole space. Then, we have \(\sum _{k = 1}^{K} \vU _{k}\vU _{k}^\top = \bm I\). Hence, (5.2.10) becomes
where MSSA is defined through an SSA operator as follows:
Substituting (5.2.13) into (5.2.7) yields that it can naturally be approximated by
Remark 5.7. The SSA operator in (5.2.14) resembles the attention operator in a typical transformer [VSP+17b], except that here the linear operators of value, key, and query are all set to be the same as the subspace basis, i.e., \(\vV _{k} = \vK _{k} = \bm {Q}_{k} = \vU _k^*\). Hence, we name \(\mathrm {SSA}({\spcdot \mid \vU _k}): \bR ^{d\times n} \rightarrow \bR ^{p\times n}\) the Subspace Self-Attention (SSA) operator. Then, the whole MSSA operator in (5.2.15), formally defined as \(\mathrm {MSSA}({\spcdot \mid \vU _{[K]}}) \colon \bR ^{d \times n} \to \bR ^{d \times n}\) and called the Multi-Head Subspace Self-Attention (MSSA) operator, aggregates the attention head outputs by averaging using model-dependent weights, similar in concept to the popular multi-head self-attention operator in existing transformer networks. The overall gradient step (5.2.16) resembles the multi-head self-attention implemented with a skip connection in transformers.
MLP as proximal gradient descent for sparse coding of token representations. For the second step of alternating minimization, we need to minimize \(\lambda \norm {\vZ }_{1} - R_{\epsilon }(\vZ )\). Note that the gradient \(\nabla R_{\epsilon }(\vZ )\) involves a matrix inverse, and thus naive proximal gradient (see Section A.1.3) to optimize this problem becomes intractable on large-scale problems. We therefore take a different approach to trading off between representational diversity and sparsification: we posit a (complete) incoherent or orthogonal dictionary \(\vD ^{\ell } \in \bR ^{d \times d}\), and ask to sparsify the intermediate iterates \(\vZ ^{\ell + 1/2}\) with respect to \(\vD ^{\ell }\). That is, \(\vZ ^{\ell + 1/2} \approx \vD ^{\ell } \vZ ^{\ell + 1}\) where \(\vZ ^{\ell + 1}\) is more sparse; that is, it is a sparse encoding of \(\vZ ^{\ell + 1/2}\). The dictionary \(\vD ^{\ell }\) is used to sparsify all tokens simultaneously. By the incoherence assumption, we have \((\vD ^{\ell })^\top (\vD ^{\ell }) \approx \vI \). Thus from (5.2.2) we have
To solve \(\lambda \norm {\vZ }_{1} - R_{\epsilon }(\vZ )\), we optimize the following problem
The above sparse representation program is usually solved by relaxing it to an unconstrained convex program, known as LASSO [WM22]:
In our implementation, we also add a non-negative constraint to \(\vZ ^{\ell + 1}\), and solve the corresponding non-negative LASSO:
Then, we incrementally optimize Equation (5.2.16) by performing an unrolled proximal gradient descent step, known as an ISTA step [BT09], to give the update:
We now design a white-box transformer architecture, named the Coding RATE Transformer (CRATE), by unrolling the above updates. By combining the above two steps (5.2.16) and (5.2.20):
we can get the following rate-reduction-based transformer layer, illustrated in Figure 5.13,
Composing multiple such layers following the incremental construction of our representation in (5.2.6), we obtain a white-box transformer architecture that transforms the data tokens towards a compact and sparse union of incoherent subspaces, where \(f^{\pre }: \bR ^{D \times N} \rightarrow \bR ^{d \times N}\) is the pre-processing mapping that transforms the input tokens \(\vX \in \bR ^{D \times N}\) to first-layer representations \(\vZ ^{1} \in \bR ^{d \times N}\). An overall flow of this architecture was shown in Figure 5.14.
Remark 5.8 (The roles of the forward pass and backward propagation). In contrast to other unrolled optimization approaches such as the ReduNet [CYY+22], we explicitly model the distribution of each \(\vZ ^\ell \) and \(\vZ ^{\ell + 1/2}\) at each layer, either by a mixture of linear subspaces or sparsely generated from a dictionary. We introduced the interpretation that at each layer \(\ell \), the learned bases for the subspaces \(\vU _{[K]}^{\ell }\) and the learned dictionaries \(\vD ^{\ell }\) together serve as a codebook or analysis filter that encodes and transforms the intermediate representations at each layer \(\ell \). Since the input distribution to layer \(\ell \) is first modeled by \(\vU _{[K]}^{\ell }\) then transformed by \(\vD ^{\ell }\), the input distribution to each layer is different, and so we require a separate codebook at each layer to obtain the most parsimonious encoding. Parameters of these codebooks (i.e., the subspace bases and the dictionaries), heretofore assumed as being perfectly known, are actually learned from data (say via backward propagation within end-to-end training).
Hence, our methodology features a clear conceptual separation between forward “optimization” and backward “learning” for the so-derived white-box deep neural network. Namely, in its forward pass, we interpret each layer as an operator which, conditioned on a learned model (i.e., a codebook) for the distribution of its input, transforms this distribution towards a more parsimonious representation. In its backward propagation, the codebook of this model, for the distribution of the input to each layer, is updated to better fit a certain (supervised) input-output relationship, as illustrated in Figure 5.15. This conceptual interpretation implies a certain agnosticism of the model representations towards the particular task and loss; in particular, many types of tasks and losses will ensure that the models at each layer are fit, which ensures that the model produces parsimonious representations.
There are three natural questions we can ask about CRATE:
We contend that the answer to each question is “yes”. First, Figure 5.16 examines how the network optimizes each term of the sparse rate reduction; each layer consistently decreases the features’ compression measure and sparsity measures during the forward pass. Second, in Table 5.1 we demonstrate that CRATE has comparable top-1 classification accuracy under transfer learning setups to the most commonly used Vision Transformer (ViT) [DBK+21] neural network architecture at similar parameter counts, with promising scaling behavior — we obtain steady and consistent improvements by increasing the model size. Overall, CRATE achieves promising performance on real-world large-scale datasets by directly implementing our principled architecture. We provide more details of the implementation and analysis of the experimental results in Section 8.4.
| Model | CRATE-T | CRATE-S | CRATE-B | CRATE-L | ViT-T | ViT-S |
| # parameters | 6.09M | 13.12M | 22.80M | 77.64M | 5.72M | 22.05M |
| ImageNet-1K | 66.7 | 69.2 | 70.8 | 71.3 | 71.5 | 72.4 |
| ImageNet-1K ReaL | 74.0 | 76.0 | 76.5 | 77.4 | 78.3 | 78.4 |
| CIFAR10 | 95.5 | 96.0 | 96.8 | 97.2 | 96.6 | 97.2 |
| CIFAR100 | 78.9 | 81.0 | 82.7 | 83.6 | 81.8 | 83.2 |
| Oxford Flowers-102 | 84.6 | 87.1 | 88.7 | 88.3 | 85.1 | 88.5 |
| Oxford-IIIT-Pets | 81.4 | 84.9 | 85.3 | 87.4 | 88.5 | 88.6 |
So far, we wish that we have provided compelling evidence that the role of (popular) deep networks is to realize certain optimization algorithms for minimizing the coding rate (or maximizing the information gain) of the learned representations. However, readers who are familiar with optimization methods might have noticed that the above architectures (the ReduNet or the CRATE) correspond to rather basic optimization techniques. They may have plenty of room for improvement in efficiency or effectiveness. Moreover, if we believe the proposed theoretical framework for interpreting deep networks is correct, it should not only help explain existing architectures, it should guide us develop more efficient and effective architectures. In this section, we show this is the case: the resulting new architectures are not only fully interpretable but also with guaranteed correctness and improved efficiency.
In this subsection, we ask and answer the question: “what is the simplest possible neural network which scales reasonably well and provably compresses the representation?” From our previous theory, the answer should be a stack of MSSA layers, which were motivated as lossy compression operator. This network architecture is simple enough such that it is possible to analyze the compression or denoising performance rigorously and systematically. Towards this end, let us formalize our subspace model: the initial token representations \(\bm Z^{1}\) are sampled from a noisy mixture of low-rank Gaussians, supported on subspaces spanned by \(\vU _{k} \in \R ^{d \times p}\), as follows: we partition the \(N\) token indices into known subsets \(C_{1}, \dots , C_{K}\), such that:
where \(\bm {a}_i \overset {i.i.d.}{\sim } \mathcal {N}(\bm {0},\bm {I}_{p_k})\) and \(\bm {e}_{i,j} \overset {i.i.d.}{\sim } \mathcal {N}(\bm {0},\delta ^2\bm {I}_{p_j})\) for all \(i \in C_k\) and \(k \in [K]\), \(\{\bm {a}_i\}\) and \(\{\bm {e}_{i,j}\}\) are all independent.
Denoising operator for token representations. Now, we show that the MSSA operator (see (5.2.15)) can incrementally denoise token representations generated from the above model. Specifically, we consider a generalized MSSA operator: for each \(\ell \in [L]\),
where \(\eta > 0\) is the step size, and \(\varphi \) is a function operating on each column of the input matrix, such as softmax, element-wise ReLU, etc. To simplify our theory, we assume that the subspaces in Equation (5.3.1) are orthogonal to each other, i.e., \(\bm U_k^T\bm U_j = \bm 0\) for all \(k \neq j\). Note that this assumption is not restrictive, as in high-dimensional spaces, random low-dimensional subspaces are incoherent to each other with high probability, i.e., \(\bm U_k^T\bm U_j \approx \bm 0\) [WM22].19
Now, let the columns of \(\bm Z_k^{\ell }\) denote the token representations from the \(k\)-th subspace at the \(\ell \)-th layer. To quantify the denoising capability, we define the signal-to-noise ratio (SNR) for each block of the token representations at the \(\ell \)-th layer as follows:
To simplify our analysis, we assume that \(\abs {C_{1}} = \cdots = \abs {C_{K}} =N/K\), and
With the above setup, we can now characterize the denoising performance of a slightly modified MSSA operator, which thresholds terms which are too small in the softmax.
Theorem 5.1. Let \(\bm Z^{1}\) be defined in Equation (5.3.1) and \(\varphi (\cdot )\) in (5.3.2) be \(\varphi (\bm x) = h\left (\sigma (\bm x)\right )\), where \(\sigma :\R ^N \to \R ^N\) is the softmax function and \(h:\R ^N \to \R ^N\) is an element-wise thresholding function with \(h(x) = \tau \) if \(x > \tau \) and \(h(x) = 0\) if \(x \leq \tau \) for each \(i \in [N]\). Suppose that \(p \gtrsim \log N\), \(\delta \lesssim \sqrt {\log N}/\sqrt {p}\), and
For sufficiently large \(N\), it holds with probability at least \(1-KLN^{-\Omega (1)}\) that for each \(\ell \in [L]\),
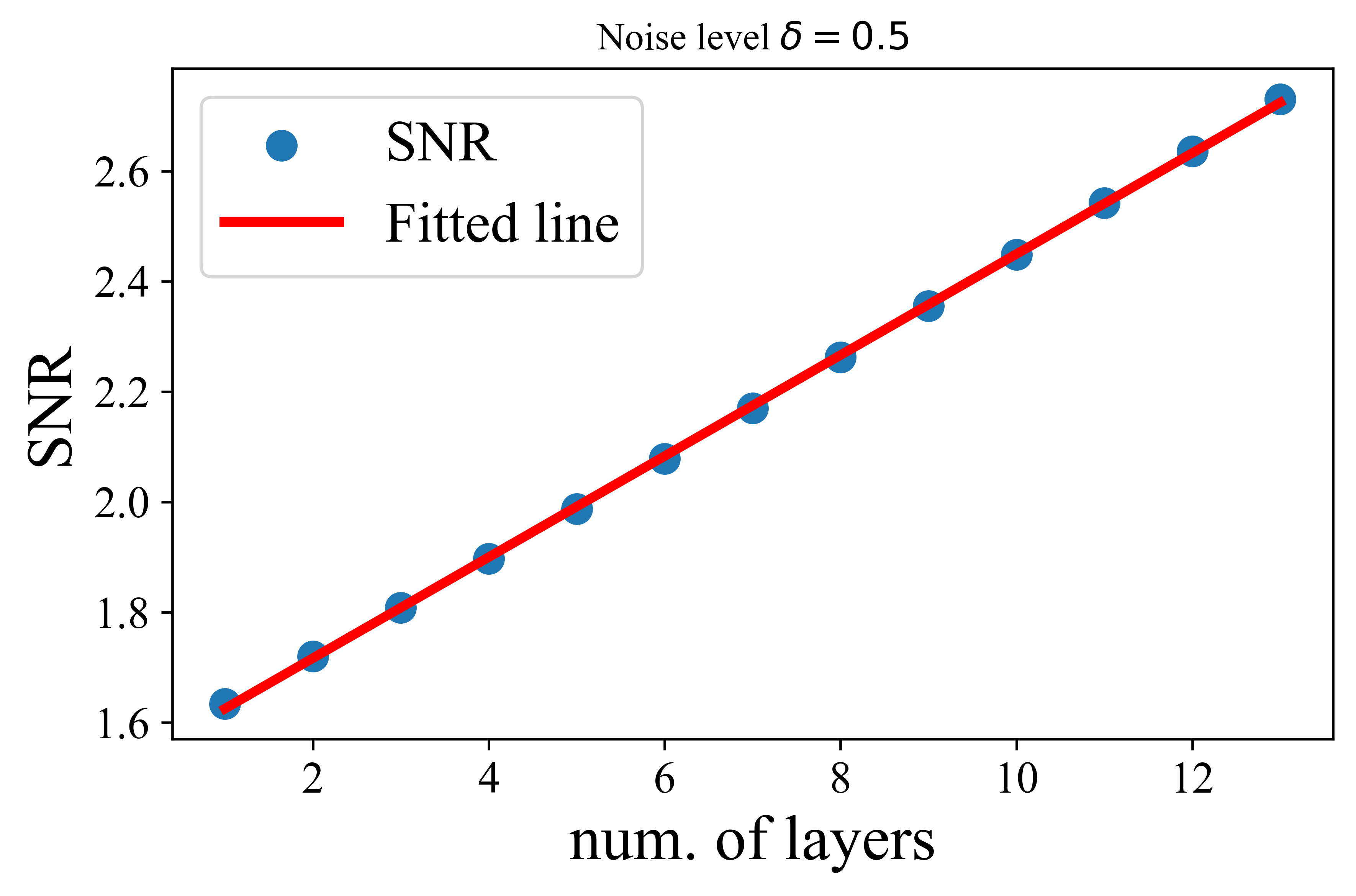
This theorem demonstrates that when the initial token representations are sampled from a mixture of low-rank Gaussian distributions with a noise level \(O(\sqrt {\log N}/\sqrt {p})\), we show that each application of the modified MSSA operator denoises token representations at a linear rate. Notably, our theoretical results are well-supported by experimental observations using the actual MSSA operator in Figure 5.18. This theorem provides a theoretical foundation for the practical denoising capability of the transformer architecture derived by unrolling (5.3.2).
Attention-only transformers. To verify that this denoising capability translates to reasonable performance on real data and tasks, we formally propose an attention-only transformer architecture, which we short-hand as AoT. Specifically, by unrolling the iterative optimization steps (5.3.2) as layers of a deep network, we construct a transformer architecture in Figure 5.19. Each layer of the proposed architecture only consists of the MSSA operator and a skip connection. For language tasks, we additionally incorporate LayerNorm before the MSSA operator to improve performance. The complete architecture is built by stacking such layers, along with essential task-specific pre-processing and post-processing steps, such as positional encoding, token embedding, and a final task-specific head to adapt to different applications. Table 5.2 and demonstrates the performance of this minimalist transformer on vision classification; the performance is reasonable, despite the minimalist design. In the sequel, we will discuss a conceptual improvement to the CRATE formulation which also improve the performance and efficiency.
| Models | Accuracy | # of Parameters |
| AoT | 71.7% | 22M |
| CRATE | 79.5% | 39M |
| ViT | 72.4 % | 22M |
In this subsection, we propose a new transformer attention operator whose computational complexity scales linearly with the number of tokens based on the coding rate reduction objective. Specifically, we derive a novel variational form of the MCR\(^2\) objective and show that the architecture that results from unrolled gradient descent of this variational objective leads to a new attention module called Token Statistics Self-Attention (TSSA). TSSA has linear computational and memory complexity and radically departs from the typical attention architecture that computes pairwise similarities between tokens. Replacing a traditional attention operator in a transformer with TSSA yields a new neural network architecture called the Token Statistics Transformer (ToST), which is highly efficient and has promising empirical performance. As a preliminary, recall from (4.2.17) that \(\bm \Pi = [\bm \pi _1, \ldots , \bm \pi _K] \in \R ^{N \times K}\) denotes a stochastic “group assignment” matrix (i.e., \(\bm \Pi \bm 1 = \bm 1\) and \(\Pi _{ik} \geq 0, \ \forall (i,k) \in [N] \times [K]\)), where \(\Pi _{ik}\) denotes the probability of assigning the \(i\)-th token to the \(k\)-th group.
A new variational form for coding rates. To begin, we consider a general form of MCR\(^2\)-like objectives based on concave functions of the spectrum of a matrix. Namely, for a given PSD matrix \(\bm M \in \PSD (d)\) and any scalar \(c \geq 0\) we have that \(\log \det (\I + c \bm M) = \sum _{i=1}^{d} \log ( 1 + c \lambda _i(\bm M))\), where \(\lambda _i (\bm M)\) is the \(i\)-th largest eigenvalue of \(\bm M\). Further, note that \(\log (1 + c \sigma )\) is a concave non-decreasing function of \(\sigma \). Thus, we describe our results in terms of a more general form of MCR\(^2\) based on general spectral functions of PSD matrices of the form \(F(\bm M) = \sum _{i=1}^{d} f(\lambda _i(\bm M))\), where \(f\) is concave and non-decreasing. In particular, recall from earlier in this Chapter that the attention mechanism arises from unrolling the compression component of MCR\(^2\), so we consider a more general MCR\(^2\)-style compression function:
For the above objective, we now note the following result:
Theorem 5.2. Let \(f \colon [0, \infty ) \to \R \) be non-decreasing, concave, and obey \(f(0) = 0\), and let \(F \colon \PSD (d) \to \R \) have the form \(F(\bm M) = \sum _{i = 1}^{d}f(\lambda _{i}(\bm M))\). Then for each \(\bm M \in \PSD (d)\) and \(\bm Q \in \O (d)\), we have
Using the above result, we can replace (5.3.6) with an equivalent variational objective with form
where the equivalence is in the sense that for an optimal choice of \(\{ \bm U_k \in \O (d)\}_{k=1}^K\) matrices as described in Theorem 5.2 (i.e., orthogonal matrices which diagonalize each \(\Z \mathrm {Diag}(\bm \pi _k) \Z ^\top \)) we will achieve a tight bound with \( R^{\rm var}_{c,f} (\Z ,\bm \Pi \mid \bm U_{[K]}) = R_{c,f} (\Z ,\bm \Pi )\). Note that in general, achieving this bound would require selecting, for each sampled instance of \(\Z \), a new optimal set of \(\bm U_{k}\) parameter matrices which diagonalize each \(\Z \mathrm {Diag}(\bm \pi _{k})\Z ^{\top }\), which is clearly impractical for network architecture. Instead, as an alternative viewpoint, rather than considering the data (\(\Z \)) as fixed and trying to optimize the \(\bm U_k\) parameters to achieve the tight variational bound, we can instead take the algorithmic unrolling design principle described above and design an operator to perturb \(\Z \) to incrementally minimize \(R_{c, f}^{\rm var}(\cdot \mid \bm U_{[K]})\). To make this point explicit, each variational bound becomes tight when the eigenspaces of \(\Z \mathrm {Diag}(\bm \pi _k) \Z ^\top \) align with the columns of \(\bm U_k\), so by rotating the appropriate columns of \(\Z \) (namely, those which correspond to large entries in \(\bm \pi _k\)) to align with \(\bm U_k\) we can approach a tight variational bound. That is, instead of rotating \(\bm U_k\) to align with the data for each instance of \(\Z \), we can instead rotate the token features in each \(\Z \) to align with \(\bm U_k\).
Following this approach, we compute a gradient descent step on \(R_{c,f}^{\rm var}\) w.r.t. \(\Z \). To begin this computation, first let \(\bm \pi \in \Re ^N\) be any element-wise non-negative vector. Then we have
where \(\nabla f\) is the gradient of \(f\), and (recall) \(\nabla f[\cdot ]\) applies \(\nabla f\) to each element of the vector in the bracket. In particular, for \( f(x) = \log (1 + (d/\epsilon ^{2}) x)\), \(\nabla f(x) = (d / \epsilon ^{2}) (1+ (d / \epsilon ^{2}) x)^{-1}\) is simply a non-linear activation. Also, (recall) \(N_{k} = \langle \bm \pi _{k}, \bm 1\rangle \). Thus, the gradient of \(R^{\rm var}_{c,f}\) w.r.t. \(\Z \) is:
(Note that the \(1/N\) constant arises from a \((N_{k}/N)\cdot (1/N_{k}) = 1/N\) constant in each term of the sum.) If we now consider a gradient step w.r.t. the \(j\)-th token \(\z _j\) , we arrive at our proposed incremental compression operator, i.e., our surrogate for a self attention + residual operator:
for each \(j \in [n]\), where \(\tau > 0\) is a step size parameter for the incremental optimization.
Model interpretation. Given the proposed attention operator in (5.3.12), first recall that the rows of \(\bm \Pi \) are non-negative and sum to 1 , so our operator takes a weighted average of \(K\) “attention head”-esque operators and then adds a residual connection. Using that \(\sum _{k = 1}^{K}\Pi _{jk} = 1\), we can rewrite (5.3.12) as:
That is, we can view each attention head as first projecting the token features onto the basis \(\bm U_{k}\) via multiplying by \(\bm U_k^\top \), multiplying by the diagonal matrix \(\bm D(\Z , \bm \pi _{k} \mid \bm U_{k})\) (abbreviated as \(\bm D_{k}\)), projecting back into the standard basis via multiplying by \(\bm U_{k}\), and subtracting this from the original token features via the residual connection. The core aspect of our attention layer is the computation of \(\bm D_{k}\). Namely, \(\Pi _{jk} \geq 0\), so \(\bm \pi _k / \langle \bm \pi _{k}, \bm 1\rangle \in \Re ^N\) forms a probability distribution over which tokens belong to the \(k^\text {th}\) group. As a result, \((\bm U^\top _k \Z )^{\hada 2} \bm \pi _k / \langle \bm \pi _{k}, \bm 1\rangle \) estimates the second moment of \(\bm U_k^\top \Z \) under the distribution given by \(\bm \pi _k / \langle \bm \pi _{k}, \bm 1\rangle \). Further, since \(f\) is a concave non-decreasing function, \(\nabla f(x)\) monotonically decreases towards \(0\) as \(x\) increases, so the entries of \(\bm D_{k}\) (which have form \(\nabla f(x)\)) achieve their maximum at \(x=0\) and decay monotonically to \(0\) as \(x\) increases.
From this, we arrive at the core interpretation of our attention head + residual operators \([\I - (\tau /n)\bm U_{k}\bm D_{k}\bm U_{k}^{\top }]\). Namely, this operator does an approximate low-rank data-dependent projection, where directions which have a large amount of “power” after the projection \(\bm U_k^\top \Z \) (i.e., directions which have a large second moment \((\bm U_{k}^{\top }\Z )^{\hada 2}\bm \pi _k / \langle \bm \pi _{k}, \bm 1\rangle \)) are preserved, while directions which do not are suppressed. To see this, recall that the entries of \(\bm D_k\) decrease monotonically to 0 as the second moment increases, so for directions with large second moments the attention + residual operator acts largely as the identity operator. Conversely, for directions with a small second moment, our operator subtracts a projection of the tokens along those directions, resulting in those directions being suppressed. Compared to the standard self-attention operator, our method clearly does not compute any pairwise similarities between tokens. Rather, the interactions between the tokens in \(\Z \) impact the operator solely through their contribution to the second moment statistic used to construct the \(\bm D_{k}\)’s. Nevertheless, similar to the standard self-attention operator, our method still has a clear interpretation as performing a form of compression towards a data-dependent low-rank structure, in the sense that it performs an approximate low-rank projection, where the specific directions that are suppressed are those which are not strongly aligned with other tokens in the group.
Computational considerations. Having introduced our proposed attention operator, we now discuss how it can be computed practically. First, until this point in the presentation, we have avoided discussion of how tokens are “grouped” into various attention heads via the \(\bm \Pi \) matrix, but clearly a means of constructing \(\bm \Pi \) is needed to implement our method. Additionally, our variational form in Theorem 5.2 requires the \(\bm U\) matrices to be square and orthogonal, but one would ideally like to use smaller matrices (i.e., reduce the number of columns in \(\bm U\)) for efficiency as well as drop the orthogonality constraints.
In practice, we do not enforce the orthogonality constraints. To reduce the number of columns in the \(\bm U\) matrices, we note that similar to CRATE [YBP+23], if we assume the features \(\bm Z\) within group \(k\) are (approximately) clustered around a low-dimensional subspace — say of dimension \(p\) — then the within-group-\(k\) covariance \(\Z \mathrm {Diag}(\bm \pi _{k})\Z ^{\top }\) is low-rank, where recall that [YCY+20] shows that the optimal geometry of \(\Z \) will be for each group to be a low-rank subspace, orthogonal to the other groups. We can thus explicitly find a low-dimensional orthonormal basis for the image of this covariance, i.e., the linear span of the data in group \(k\). If the dimension is \(p \leq d\), the basis can be represented by a \(d\times p\) orthogonal matrix \(\bm U_k \in \O (d, p)\). In this case, we can more efficiently upper-bound \(R_{c,f}\) using these low-rank orthogonal basis matrices. To show this, we use a more general version of Theorem 5.2 to yield the following corollary.
Corollary 5.1. Let \(f \colon [0, \infty ) \to \R \) be non-decreasing, concave, and obey \(f(0) = 0\), and let \(F \colon \PSD (p) \to \R \) have the form \(F(\bm M) = \sum _{i = 1}^{p}f(\lambda _{i}(\bm M))\). Let \(\Z \), \(\bm \Pi \) be fixed. Then, for all \(\bm U_{1}, \dots , \bm U_{K} \in \O (d, p)\) such that \(\mathrm {image}(\Z \diag (\bm \pi _{k})\Z ^{\top }) \subset \mathrm {image}(\bm U_{k})\) for all \(k \in [K]\), we have
The final step to define our attention operator is to estimate the group membership \(\bm \Pi \). For this we posit a simple model of how each feature \(\z _{j}\) deviates from its supporting subspace and then find the optimal subspace assignment. [YBP+23] show that if we independently model each \(\z _{j}\) as belonging to a low-dimensional Gaussian mixture model, where each Gaussian has a covariance matrix with identical spectrum and is supported on a subspace with orthonormal basis \(\bm U_{k}\), plus independent Gaussian noise with covariance \(\eta \I \), then the posterior probability that each token \(\z _{j}\) belongs to each subspace is given by the assignment matrix \(\bm \Pi = \bm \Pi (\bm Z \mid \bm U_{[K]})\) as follows:
where \(\eta \) becomes a learnable temperature parameter. Thus, given an input feature \(\Z \), we estimate \(\bm \Pi \) using (5.3.16) and then compute the attention operator. Combining the construction of \(\bm \Pi \) in (5.3.16) with (5.3.12), we obtain the Token Statistics Self-Attention operator:
where \(\bm \pi _{k}\) are the columns of \(\bm \Pi = \bm \Pi (\Z \mid \bm U_{[K]})\) defined in (5.3.16) and \(\bm D\) is defined in (5.3.10).
By starting with a standard Transformer architecture and replacing the attention operator with TSSA, we obtain an architecture called Token Statistics Transformer (ToST), visualized in Figure 5.20. We would like to re-emphasize that the TSSA operator mitigates the usual time and memory complexity of the attention operator, in particular reducing the quadratic time and memory complexity to linear, which makes ToST much more efficient than its empirically designed counterpart. We now briefly show the empirical performance and efficiency of the ToST architecture.
| Datasets | ToST-T(iny) | ToST-S(mall) | ToST-M(edium) | ViT-S | ViT-B(ase) |
| # parameters | 5.8M | 22.6M | 68.1M | 22.1M | 86.6 M |
| ImageNet | 67.3 | 77.9 | 80.3 | 79.8 | 81.8 |
| ImageNet ReaL | 72.2 | 84.1 | 85.6 | 85.6 | 86.7 |
| CIFAR10 | 95.5 | 96.5 | 97.5 | 98.6 | 98.8 |
| CIFAR100 | 78.3 | 82.7 | 84.5 | 88.8 | 89.3 |
| Oxford Flowers-102 | 88.6 | 92.8 | 94.2 | 94.0 | 95.7 |
| Oxford-IIIT-Pets | 85.6 | 91.1 | 92.8 | 92.8 | 94.1 |
| Model | ListOps | Text | Retrieval | Image | Pathfinder | Avg |
| Reformer | 37.27 | 56.10 | 53.40 | 38.07 | 68.50 | 50.56 |
| BigBird | 36.05 | 64.02 | 59.29 | 40.83 | 74.87 | 54.17 |
| LinFormer | 16.13 | 65.90 | 53.09 | 42.34 | 75.30 | 50.46 |
| Performer | 18.01 | 65.40 | 53.82 | 42.77 | 77.05 | 51.18 |
| Transformer | 37.11 | 65.21 | 79.14 | 42.94 | 71.83 | 59.24 |
| ToST | 37.25 | 66.75 | 79.46 | 46.62 | 69.41 | 59.90 |
Some of the most popular applications of deep networks are in the regimes of sequence data where, unlike the previous example of imagery, there is a natural order to the data. For example, unlike in imagery (where one tends to look at the whole image at once), language is processed one token at a time (causally). This simple fact motivates the development of large language models (LLMs), which are trained to predict the (probability distribution of) the next token in a sequence given only the history of previous tokens. Then, to sample from an LLM, one simply iteratively samples from the predicted distribution for the next token and then appends the sampled token to the history. In order to train LLMs, and other models such as video generation models, it is necessary to develop architectures which can efficiently perform this causal computation.
With this in mind, and the understanding of causal autoregressive processes from Chapter 1, we say that an encoder \(f\) is causal if for every input \(\vX = [\vx _{1}, \dots , \vx _{N}]\), it holds
where \(\vZ _{1:N-1} = [\vz _{1}, \dots , \vz _{N-1}]\), etc. In English, this means that the first \(N-1\) features are equal to the output of the encoder on the first \(N-1\) token embeddings of the input; even simpler, it means we can compute the features of each token one at a time, and this would be equivalent to computing the features for the entire input. This causality is necessary for the previously mentioned applications (e.g., LLMs). In particular, the previously presented implementations of CRATE and ToST are not causal (proof is left as an exercise).
We can construct causal white-box architectures by a variety of methods. Here, we will showcase a simple method which builds on our previous unrolled optimization framework. Specifically, we compute the features \(\vz _{1}, \dots , \vz _{N}\) corresponding to the first \(N\) tokens of the input one-at-a-time to optimize the representation learning objective, such as the sparse rate reduction (5.2.5):
If we follow through with the two-step unrolling procedure that yielded CRATE, we can obtain the iteration:
or, using the same conversion from these two steps to network operators that we used for CRATE,
Let us investigate this iteration in slightly more detail. First, let us note that by construction, this sequence of features corresponds to a causal encoder. Next, let us suppose that we are in a setting where we have computed \(\vZ _{1:i-1}^{\ell + 1} = [\vz _{1}^{\ell + 1}, \dots , \vz _{i-1}^{\ell + 1}]\), having computed the quantities
along the way, and want to compute \(\vz _{i}^{\ell + 1}\) (for instance relevant to the case of LLM inference). In this case, note that the update rule for \(\vz _{i}^{\ell + 1/2}\) can be simplified as:
This step now becomes highly efficient if we cache \(\vU _{k}^{\top }\vZ _{1:i-1}\) from previous steps, and add a single column to it each time we compute the projection \(\vU _{k}^{\top }\vz _{i}\). Namely, we greatly reduce the number of large matrix-matrix products and replace them by cache loads and matrix-vector products, which is overall much cheaper in terms of time complexity. This caching is the reason why causal generative models such as LLMs can efficiently sample 1000s of tokens per second, even if each training step takes a few seconds by itself. The cache for the subspace projections of the features is also known as the so-called “KV cache”.
Finally, let us consider the case where we are to train a causal CRATE model, and want to find the most efficient way to do this given a full input sequence \(\vX = [\vx _{1}, \dots , \vx _{N}]\) simultaneously. The ISTA step is parallelizable to become the regular ISTA step from the non-causal CRATE, i.e.,
therefore implying that the ISTA step remains the same as the non-causal CRATE. The MSSA step is more interesting, since it changes in a meaningful way. To see how it changes, note that each MSSA operator has an interesting structure which merits some attention. Namely, if we define the causal MSSA operator as the block matrix:
then, working our way through the softmax algebra (proof is again left as an exercise), we can show that
Here the matrix \(\vM _{N} \in \R ^{N \times N}\) is another way to encode that no feature in CMSSA, i.e., the causal MSSA, depends on a future feature, since the relevant entries of the argument to the softmax are \(-\infty \), and thus are set to \(0\) after the exponential within the softmax, and therefore effectively ignored. This matrix \(\vM _{N}\) is sometimes called a (causal) attention mask.
The upshot of this is that when we have the full sequence \(\vZ ^{\ell }\), we can compute \(\vZ ^{\ell + 1}\) in time similar to or less than that of the usual CRATE layer (since \(\vM _{N}\) is hard-coded, input-independent, and enables us to ignore many entries for the softmax). Thus, we can define and train the full sequence-to-sequence model in the same way as the regular architecture.
When we apply this to language modeling (details to be provided in Chapter 8), we find that we can obtain reasonable results compared to similar-sized empirically designed language models, as shown in Table 5.5.
| #parameters | OWT | LAMBADA | WikiText | PTB | Avg | |
| GPT2-Base | 124M | 2.85 | 4.12 | 3.89 | 4.63 | 3.87 |
| GPT2-Small | 64M | 3.04 | 4.49 | 4.31 | 5.15 | 4.25 |
| Causal-CRATE-Base | 60M | 3.37 | 4.91 | 4.61 | 5.53 | 4.61 |
Despite the theoretical advantages of the causal CRATE architecture, the gap on language modeling (and more generally sequence modeling) tasks still remains. Below, we discuss two strategies for potentially closing this gap; they are each the subject of active lines of research.
Example 5.3 (Better Objectives and Unrolling Strategies). One path to consider is that the objective of the sparse rate reduction is not the best for causal sequence data. For example, we may want to ensure that the features have some kind of temporal relationships or structure, e.g., being generated by a linear dynamical system with Gaussian (mixture) initialization and Gaussian step noise. There is a recent but explosively popular line of work on efficiently and explicitly modeling dynamics in the features using so-called state-space models (SSMs, named such in contravention of the classical notion of “state space models” discussed in Chapter 1) [GD24; YKH24; YWZ+24]. Such models are empirically promising because they avoid the need for all-pairs attention, dodging the computational and memory complexity of the MSSA operator and its conventional cousin, the multi-head attention. Despite this efficiency gain, they are highly performant and have even been used in some large-scale language models [TZL+25]. By designing more sophisticated objectives and unrolling strategies, we may be able to build a “white-box” SSM architecture, or SSM-transformer hybrid, and thusly close the gap on causal tasks. \(\blacksquare \)
Example 5.4 (Inference-Time Computation Strategies). Another path to improve causal models is to use more so-called inference-time compute strategies: during inference (such as sampling from an LLM) find a way to spend more computational resources in order to obtain a better result. If we are able to do this, we can solve harder problems by allocating more compute to the task at hand.
One naive approach to this is to loop the model: feed the final features into the initial sequence-to-sequence layers and enable it to go through more rounds of iterative denoising. This methodology is known in the literature as “looped transformers” (for the case in which the backbone model is an empirically-designed transformers); this approach has been shown to have benefits at some particularly difficult tasks [GRS+23; SDL+25; YLN+23]. However, from our perspective it is more reasonable to loop the iterate through the same layer multiple times, taking multiple local denoising or compression steps against the same model at each layer before going to the next.
Still another potential methodology relies on our understanding of the low-dimensional structure in the features and model parameters. For example, since the \(\vU _{[K]}\) matrices are supposed to be supports for the subspaces spanned by the features, we could update them at inference-time using an online algorithm such as online (G)PCA. Similar steps may be able to adapt the dictionary at inference time. This would allow us to improve and specialize our local denoising or compression operators at each layer for the features, and thus potentially yielding better performance.
There have been many empirical attempts to improve inference-time compute methods. It is still a very active area of ongoing research. \(\blacksquare \)
The materials presented in this chapter are based on a series of recent works on this topic, including [CYY+22; WLP+24; WLY+25; WDL+25; YBP+23]. These contributions encompass both theoretical advances and practical methodologies for constructing interpretable deep networks through unrolled optimization. Many of the key results and proofs discussed in this chapter are derived directly from, or inspired by, these foundational works.
The idea of unrolling an optimization algorithm to construct a neural network traces back to the seminal work [GL10]. In this work, the authors demonstrated that sparse coding algorithms—such as the Iterative Shrinkage-Thresholding Algorithm (ISTA)—can be unrolled to form multilayer perceptrons (MLPs), effectively bridging iterative optimization and neural network design. Notably, [MLE19] demonstrated that such unrolled networks are more interpretable, efficient, and effective compared to generic networks.
In this chapter, we build on this perspective to develop principled, white-box deep network architectures by unrolling optimization algorithms that are designed to minimize well-motivated objectives—such as the (sparse) rate reduction objective introduced earlier. This approach not only clarifies the role of each layer in the network but also offers theoretical grounding for architectural choices, moving beyond empirical trial-and-error toward interpretable and goal-driven design. In the following, we compare conventional DNNs, which are typically constructed through empirical design and heuristic tuning, with our mathematically grounded ReduNet architectures:
| Conventional DNNs | ReduNets | |
| Objectives | input/output fitting | information gain |
| Deep architectures | trial & error | iterative optimization |
| Layer operators | empirical | projected gradient |
| Shift invariance | CNNs+augmentation | invariant ReduNets |
| Initializations | random/pre-design | forward unrolled |
| Training/fine-tuning | back prop | forward/back prop |
| Interpretability | black box | white box |
| Representations | hidden/latent | incoherent subspaces |
Exercise 5.1. Let \(\bm Z = [\bm Z_1,\dots ,\bm Z_K] \in \R ^{d\times N}\) with \(\bm Z_k \in \R ^{d\times N_k}\) for each \(k \in [K]\). For some \(\alpha > 0\), let
where \(\bm X \doteq \bm I + \alpha \bm Z\bm Z^\top \). Hint: Note that
where the equality holds if and only if \(\bm Z_k^\top \bm Z_l = \bm 0\) for all \(k \neq l \in [K]\).
Hint: Let \(r_k=\mathrm {rank}(\bm Z_k)\). Consider the following singular value decomposition of \(\bm Z_k\):
Exercise 5.2 (Neumann series for matrix inverse). Let \(\bm A \in \mathbb {R}^{n\times n}\). If \(\|\bm A\| < 1\), please show
Hint: The proof consists of two steps.
Exercise 5.3. In this exercise we will consider a coding rate measure \(R_{\epsilon }^{c, \mu }\) which uses the means of the distributions, i.e., a coding rate for tokens drawn (non-i.i.d.) from the low-rank Gaussian mixture model
Exercise 5.5. Please show Corollary 5.1 when \(Kp \le d\).